编程基础之编码详解
很多初学者都遇到过 “文件显示乱码” 的情况,其多数都是由于在打开文件时,没有选对 文件编码格式 导致的。
由于文本文件,是由一个个字符构成的,而字符在计算机中是采用某种特定的编码格式进行存储的(字符编码)。也就是说了解文件的 字符编码 是非常有必要的。
更多相关编程基础内容,请关注博主 Hexo 博文系列:
字符编码
学习字符编码之前,先来认识一下计算机中的字符与字节:
字符与字节
字符(chars)是人类能够识别的符号,而这些符号要能被计算机识别,处理和存储,就必须将其转化成计算机能够识别和处理的字节(Byte)。
例如:计算机要处理和存储文本,就必须先把文本转换为字节才能处理。
更多关于计算机中字节的说明,可以参考 >>>> 【计算机中信息的存储】。
计算机在设计时采用 8 个比特(bit)位作为一个字节(byte),也就是 8 位二进制数 \bxxxxxxxx(也称为 字节码)。故,一个字节能表示的最大的整数就是 255(\b11111111 = \d255 = 2^8 - 1),这就代表一个字节最多可映射 256(0~255) 个字符。
如果要映射更多的字符,就必须采用更多的字节。比如两个字节可以表示的最大整数是 65535 = 2^16 - 1(可表示 65536 个字符),4 个字节可以表示的最大整数是 4294967295 = 2^32 - 1(可表示 4294967296 个字符)等等。
何为字符编码
就是 >>>>
计算机中必然存在着一套 >>> 能将人类可识别的字符,转换为机器可识别、处理和存储的字节码的映射(规范),称为字符集(Character Set)或者字符编码(Character Encoding)。
严格来说,字符集和字符编码不是一个概念,字符集为每个字符分配了唯一的编号,而字符编码还规定了如何将字符的编号存储到计算机中。我们暂时先不讨论这些细节,姑且认为它们是一个概念。
换言之,字符编码事实上就是 >>>> 一套字符和字节码的映射规则(为每个字符分配了唯一的编号(编码值,一般采用十六进制来表示),并且它还定义了字符编号在计算机中的存储)。
你可以将字符集理解成 >>>> 一个很大的表格,它列出了所有字符和二进制字节码的对应关系,计算机显示文字或者存储文字,就是一个查表的过程。并且计算机会采用相应的字符集编码将其存储到计算机进行处理和传输。
而根据 字符编码所使用字节数 的不同,产生很多不同的字符编码:
最早的 ASCII 编码
计算机是美国人发明的,他们最先要考虑的问题是,如何将大小写英文字母、数字和一些特定符号与二进制字节码对应起来,故收录制定了标准的 ASCII 编码(American Standard Code for Information Interchange,美国信息互换标准代码)。
比如,数字 0 的编码是 48(~57),大写字母 A 的编码是 65(~90),小写字母 a 的编码是 97(-122)。
迄今为止 ASCII 码表 中 共收录了 128 个字符,用一个字节中较低的 7 个比特位(Bit)足以表示(2^7 = 128),所以还会空闲下一个比特位(奇偶校验),它就被浪费了……
ASCII 码是美国人给自己设计的,他们并没有考虑欧洲那些扩展的拉丁字母,也没有考虑韩语和日语,我大中华几万个汉字更是不可能被重视,这也是合理的,先解决自己的问题。
随着计算机技术的广泛发展,其它国家/地区编码也开始陆续出现……
兼容 ASCII 编码
其它国家或地区的字符编码都要兼容 ASCII 编码。
这是由于 ASCII 先入为主,已经使用了十来年了,现有的很多软件和文档都是基于 ASCII 的,所以后来的字符编码都是在 ASCII 基础上进行的扩展,它们都兼容 ASCII,以支持既有的软件和文档。
兼容 ASCII 的含义是 >>>>
原来 ASCII 中已经包含的字符,在其它国家/地区编码中的位置不变(也就是编码值不变),只是在这些字符的后面继续收录了新的字符,以支持既有的软件和文档。
GB2312/GBK/GB18030
再转到我们大中华,为了把中文(6W+)编码进去,可以想到要处理中文字符显然一个字节是不够的,至少需要两个字节,而且还要考虑兼容 ASCII 编码。
中文编码的三套方案 >>> GB2312 –> GBK –> GB18030 出现的时间从早到晚,收录的字符数目依次增加,并且向下兼容。
GBK 编码最牛掰,后来的 中文版 Windows 都将 GBK 作为默认的中文编码方案。可以说,GBK 编码在中文版的 Windows 中大行其道。你可以选择使用 GB2312 或者 GB18030,不过一般没有这个必要。
—> 这里产生一个问题:
你可以想得到的是,全世界有上百种语言,日本把日文编到 Shift_JIS 里,韩国把韩文编到 Euc-kr 里,各国有各国的标准,就会不可避免地出现冲突,结果就是 >>> 在多语言混合的文本中,显示出来会有乱码。
Unicode 字符集
人们迫切希望有一种字符编码可以统一世界各地的字符,计算机只要安装了这一种字符编码,就能支持使用世界上所有的文字,再也不会出现乱码,再也不需要转码了,这对计算机的数据传递来说是多么的方便!!!
Unicode(Unity Code)字符集应运而生~~~
Unicode 也称为统一码、万国码。看名字就知道,Unicode 希望统一所有国家的字符集。
Windows、Linux、Mac OS 等常见操作系统都已经从底层(内核层面)开始支持 Unicode,大部分的网页和软件也使用 Unicode,Unicode 是大势所趋。
不过由于历史原因,目前的计算机仍然安装了 ASCII 编码以及 GB2312、GBK、Big5、Shift-JIS 等地区编码,以支持不使用 Unicode 的软件或者文档。实际上,内核在处理字符时,一般会将地区编码先转换为 Unicode 码,再进行下一步处理。
我们一直在说,Unicode 是一套字符集,而不是说是一套字符编码。借鉴 【何为字符编码】 中关于字符集和字符编码的说明:
- 字符集为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程;
- 而字符编码还规定了如何将字符的编号存储到计算机中。不同的字符占用的字节数可能是不一样,那么为了区分一个字符到底使用了几个字节,就不能将字符的编号直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码。
有的字符集在制定时就考虑到了编码的问题,是和编码结合在一起的,例如 ASCII、GB2312、GBK 等,所以无论称作字符集还是字符编码都无所谓,也不好区分两者的概念。
而有的字符集只管制定字符的编号,至于怎么存储,那是字符编码的事情,Unicode 就是一个典型的例子,它只是定义了全球文字的唯一编号,因此我们还需要 UTF-8、UTF-16、UTF-32 这几种编码方案将 Unicode 存储到计算机中,或用于网络传输。
UTF-8 统一字符编码
UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode 转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
Unicode 可以使用的编码方案有三种,分别是:
- UTF-8:一种变长的编码方案,使用 1~6 个字节来存储;
- UTF-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
- UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
日常中,UTF-8 字符编码使用的最多,下面来简单认识一下。UTF-8 的编码规则很简单:
- 如果只有一个字节,那么最高的比特位为
0,这样可以兼容 ASCII; - 如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为
1,就使用几个字节编码,剩下的字节均以10开头。
具体的表现形式为:
0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;- 110xxxxx 10xxxxxx:双字节编码形式(第一个字节有两个连续的 1);
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(第一个字节有三个连续的 1);
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(第一个字节有四个连续的 1)。
xxx 就是用来存储 Unicode 中的字符编号的。
对于常用的字符,它的 Unicode 编号范围是 \u0 ~ \uFFFF(65535),用 1~3 个字节足以存储,只有及其罕见,或者只有少数地区使用的字符才需要 4~6 个字节存储。
| ================================================== Split Line =============================================== |
重新来理解一下字符、Unicode 以及各种字符编码的层次关系:
| 概念 | 层次 | 特征 |
|---|---|---|
| 字符/字符串 | 视图层/应用层 | 可读写,可理解 |
| Unicode | 逻辑层 | 统一性,一致性 |
| UTF-8,UTF-16,GBK | 物理层:内存,磁盘,网络 | 面向存储、传输 |
特别注意 >>> Unicode 是逻辑意义上的编码,每个字符都有自己的 Unicode 码,在程序中可以通过 \uXXXX 的形式来表示,与字节流无关!!!而 UTF-8/16/32 才是 Unicode 在物理层存储和传输的编码方案,对应特定的字节流。

字符编码工作模式
当然有编码就有 解码,即编码反向过程。
搞清楚了ASCII、Unicode 和 UTF-8 的关系,我们就可以可视化描述一下现在计算机系统通用的字符编码以及解码工作方式:
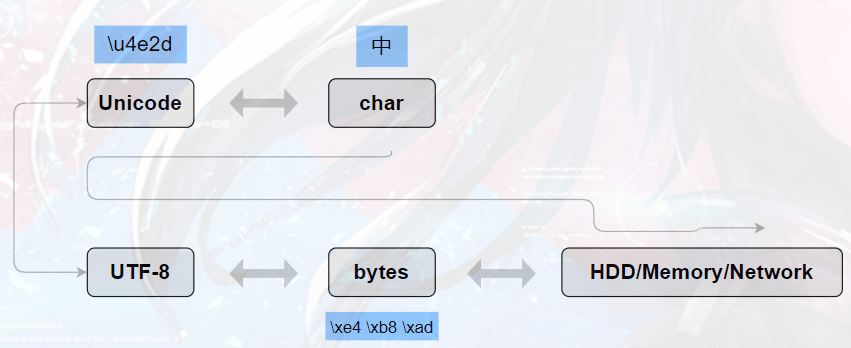
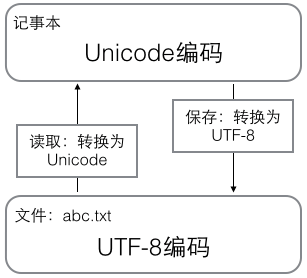
用记事本编辑的时候,从文件中读取的 UTF-8 字节流被转换为 Unicode 字符码到内存里(解码),编辑完成后,保存的时候再把 Unicode 转换为 UTF-8(编码)保存到文件:
浏览网页的时候,服务器会把动态生成的 Unicode 内容转换为 UTF-8(编码)再传输到浏览器:
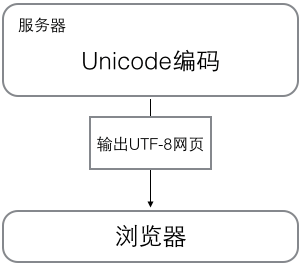
所以你看到很多网页的源码上会有类似 <meta charset="UTF-8" /> 的信息,表示该网页正是用的 UTF-8 编码。
编码和解码
编码(encode):将 Unicode 字符串转换为特定字符编码规则对应的字节串的过程。
解码(decode):将特定字符编码规则的字节串转换为对应的 Unicode 字符串的过程。
install_url to use ShareThis. Please set it in _config.yml.