一文学会正则表达式语法
正则表达式(Regular Expression)是一种 文本匹配模式(Pattern),基本上所有的程序设计语言都支持利用正则表达式进行字符串的操作,它是学习编程的基础。
博文中,为了简化,有些地方会将正则表达式简称为 >>> 正则。
什么是正则
日常中,典型的文本搜索(Search)和替换(Replace)操作,都要求你提供与预期搜索结果匹配的 确切文本,也被称为完全匹配。
而 正则表达式(Regular Expression)是一种文本(或字符串)匹配模式(Pattern),是一种模糊匹配。
↓↓↓↓↓↓ 正则表达式应用场景 ↓↓↓↓↓↓
在文本(或字符串)中,查找、替换 >>> 符合某种正则匹配模式 的子文本(子串)场景。
你可以简单的理解为 >>>
| >>> 正则就是用有限的字符,来表达无限的序列 <<< |
正则的构成
正则表达式,是由 普通字符 && 特殊字符(也称为元字符)组成的文本模式(Pattern)。
正则表达式的语法一般类似如下:
1 | # JS 中两条斜线中间是正则主体(匹配模式): |
| ================================================== Split Line =============================================== |
字符(普通字符 && 特殊字符)作为正则的基本构成,接下来需要深入了解一下字符的分类:
普通字符
区别于特殊字符,没有特殊意义的字符即简单字符。
绝大部分的字符都是简单字符,在正则中 仅表示其自身。示例如下(匹配确切文本):
1 | /abc/ // 用于匹配 abc |
特殊字符
所谓特殊字符,是指在正则中具有特殊含义的字符。
可以先跳过本章节内容,或对照下一章节内容进行学习。
正则表达式中支持的特殊字符如下:
| Characters | Description |
|---|---|
| $ | 定位符,匹配输入字符串的结尾位置。要匹配 $ 字符本身,请使用 \$ |
| ( ) | 分组,标记一个子表达式(分组)的开始和结束位置。要匹配这些字符,请使用 \( 和 \) |
| * | 量词,匹配前面的子表达式零次或多次(零次及以上)。要匹配 * 字符,请使用 \* |
| + | 量词,匹配前面的子表达式一次或多次(一次及以上)。要匹配 + 字符,请使用 \+ |
| . | 匹配除换行符 \n \r 之外的任何单字符。要匹配 . ,请使用 \. |
| [ | 标记一个中括号表达式(字符集合)的开始。要匹配 [,请使用 \[ |
| ? | 量词,匹配前面的子表达式零次或一次,或定义非贪婪模式。要匹配 ? 字符,请使用 \? |
| \ | 转义,将下一个字符标记为:转义字符、原义字符、特殊字符,或向后引用。要匹配 \ 字符,请使用 \\ |
| ^ | 定位符,匹配输入字符串的开始位置,或在字符集合 [] 中使用表示取反(非)。要匹配 ^ 字符本身,请使用 \^ |
| { | 量词,数量表达式的开始。要匹配 {,请使用 \{ |
| |
选择,两项之间的一个选择(取或)。要匹配 |,请使用 | |
转义字符详解 >>>>
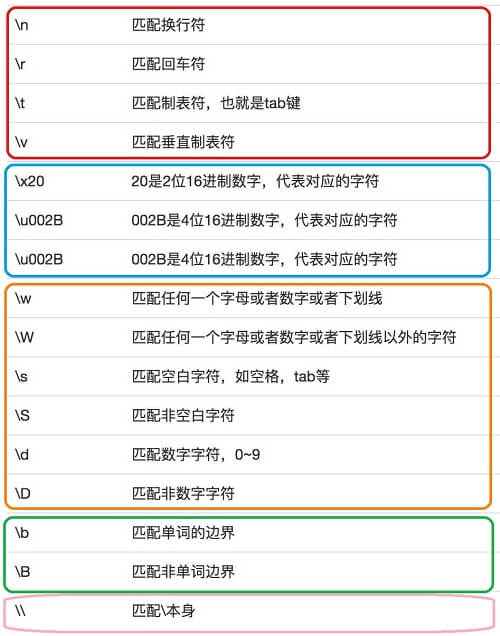
字符 \ 表示转义,其后跟的字符不同具有不同的含义,可分为四类:
- 转义字符:匹配无法显示的特殊字符,如 换行(
\n)、制表符(\t)等; - 原义字符:让特殊字符显示其自身,即匹配特殊字符本身,如
\\&&\$等; - 特殊字符:具有特殊含义,如:
\w&&\s等; - 向后引用:后跟数字表示引用。
常用转义字符支持:
正则匹配模式
正则表达式中使用不同的特殊字符,可以构建具有不同匹配规则的文本模式。
字符匹配
首先来基本的字符匹配语法:
纵向模糊匹配
纵向模糊匹配,就是 想要匹配的某个字符不确定,有多种情况(属于某个字符簇)。
方法 >>> 使用字符簇([])。如下:
1 | /[abc]/ // 可以匹配:a 或 b 或 c |
[1] >>> 字符簇范围表示法
对于很长的、且有规律的字符簇,可以使用范围表示法(-)。如下:
1 | /[0-9]/ // 等价于:[0123456789] |
[2] >>> 排除字符簇
在字符簇中的第一位写 ^,表示取非。例如:
1 | /[^abc]/ // 可以匹配:a、b、c 之外的任意字符 |
[3] >>> 常见字符簇
正则内置了 7 种常见的字符簇简写形式:
\d = [0-9]>>> 匹配数字;\D = [^0-9]>>> 匹配除数字以外的任意一个字符\w = [0-9a-zA-Z_]>>> 匹配字母、数字或下划线\W = [^0-9a-zA-Z_]>>> 匹配除字母、数字或下划线以外的任意一个字符\s = [ \t\v\n\r\f]>>> 匹配任意一个空白符(空格、制表符、换行符以及换页符)\S = [^ \t\v\n\r\f]>>> 匹配非空白符以外的任意一个字符. = [^\n\r]>>> 匹配除换行符以外的任意一个字符;
横向模糊匹配
横向模糊匹配,就是 想要匹配的某个字符,可能会连续出现多次。
方法 >>> 使用量词({m, n}),为匹配字符可连续出现 m~n 次(优先匹配 n 次)。如下:
1 | /ab{2,4}c/ // 可以匹配:abbbbc 或 abbbc 或 abbc,优先匹配 abbbbc |
[1] >>> 常见量词形式
正则内置了 5 种常见的量词简写形式:
{m}:匹配m次,等价于{m, m}。例如a{2}表示:匹配 aa;{m,}:匹配m~∞次,等价于{m, ∞},优先匹配∞次。例如a{1,}可以匹配:aaaa…;?:匹配0次或1次,等价于{0, 1},优先匹配1次(记忆:有吗?>>> 出现或不出现);+:匹配1~m次,等价于{1, m},优先匹配m次(记忆:追加 >>> 至少有一个,再追加);*:匹配0~m次,等价于{0, m},优先匹配m次(记忆:星星,可能一颗,可能几颗,可能数不清)。
[2] >>> 贪婪匹配
正则量词默认和人心一样是贪婪的,其默认是使用 贪婪模式 去匹配的,都优先匹配上限而不是下限(尽可能多)。例如:
1 | /a{1, 3}/ // 匹配字符串 `aaa` 时,会匹配 `aaa` 而不是 `a` |
如何开启 非贪婪模式匹配 >>>
有时侯,我们不希望使用贪婪模式去匹配,可以通过在量词后面加一个 ?,表示开启非贪婪模式:
1 | /a{1, 3}?/ // 匹配字符串 `aaa` 时,会匹配 `a` 而不是 `aaa` |
选择表达式
上面我们知道,上面的字符簇是对单个字符取或,例如 [abc] 可以匹配 a 或 b 或 c。
如果,我们想要对 多个字符拼成的像单词 这样的形式取或,怎么办?
方法 >>> 使用 | 构建 选择表达式 。如下:
1 | /xxx|yyy|zzz/ // 可以匹配:xxx 或 yyy 或 zzz |
需要注意的是,选择表达式会优先匹配排在前面的 “单词”,如下:
1 | /good|goodbye/ // 匹配字符串 `goodbye` 时,会匹配 `good` 而不是 `goodbye` |
修饰符
正则表达式中,可以通过在正则表达式的后面增加修饰符(flags),来指定额外的匹配策略。其语法格式如下:
1 | /pattern/flags |
额外的匹配策略?!! >>> 例如,默认情况下,正则匹配时是区分大小写的!!!你可以通过添加修饰符(i >>> ignore)来将匹配设置为不区分大小写:
1 | /ab/i // 可以匹配:ab 或 aB 或 Ab 或 AB |
正则表达式支持的其它常用修饰符 >>>
g>>> global:全局匹配策略,默认情况下正则遇到第一个匹配项就会结束;而加上全局修饰符,可以查找所有的匹配项;m>>> Multiline:多行模式,使边界字符^和$可以匹配每一行(\n&&、r)的开头和结尾;而非多行模式则只能匹配整个字符串的起始位置与结束位置;s:默认情况下的圆点.是匹配除换行符\n、\r之外的任何字符;而加上s修饰符,.中包含换行符\n&&\r。
示例如下:
1 | /JS/g // 可以匹配字符串 `Hello JS, I love JS` 中的所有 `JS` |
位置匹配
位置(锚)是指 >>> 相邻字符之间的位置。如下:
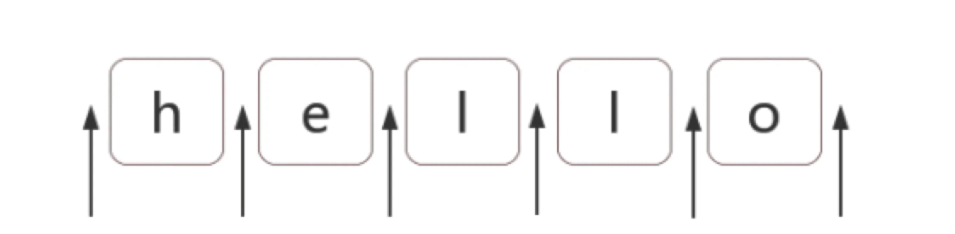
[1] 特殊位置 >>> 字符边界 >>>
1.1 字符边界】>>> ^ && $
^ 在字符簇([])外表示匹配文本开头位置的意思,代表文本开头的位置。例如,你可以匹配以某字符开头的文本:
1 | /^abc/ // 可以匹配 abcde,但是不能匹配 aabcde |
$ 表示匹配文本结尾位置的意思,代表文本的结尾位置。例如,你可以匹配以某字符结尾的文本:
1 | /abc$/ // 可以匹配 defabc,但是不能匹配 defabcc |
观察匹配位置实质 >>>
1 | // 以 JavaScript 为例: |
1.2 字符边界】>>> \b && \B
\b 表示匹配文本中的单词边界位置的意思,包括:单词和非单词之间、单词和开头之间、单词和结尾之间。
例如,你可以匹配文本中以某字符开头(结尾)的单词:
1 | /\bJS/ // 可以匹配 `Hello JS`,但是不能匹配 `HelloJS` |
而 \B 表示匹配文本中的非单词边界位置的意思,除了 \b 的位置,别的都是 \B。
观察匹配位置实质 >>>
1 | > console.log('[apple] test.mp4 你好'.replace(/\b/g, '#')); |
[2] >>> 预查(断言)
2.1 正向预查】>>> (?=pattern) && (?!pattern)
(?=pattern):表示正向肯定预查 >>> 即该位置后面的字符要匹配 pattern。
例如,Windows(?=95|98|NT|2000) 能匹配 “Windows2000” 中的 “Windows”,但不能匹配 “Windows3.1” 中的 “Windows”。
(?!pattern):表示正向否定断言。即该位置后面的字符不能匹配 pattern。
例如,Windows(?!95|98|NT|2000) 能匹配 “Windows3.1” 中的 “Windows”,但不能匹配 “Windows2000” 中的 “Windows”。
观察匹配位置实质 >>>
1 | > console.log('hello'.replace(/(?=l)/g, '#')); |
2.2 反向预查】>>>
(?<=pattern):表示反向肯定预查 >>> 即该位置前面的字符要匹配 pattern。
例如,(?<=95|98|NT|2000)Windows 能匹配 “2000Windows” 中的 “Windows”,但不能匹配 “3.1Windows” 中的 “Windows”。
(?<!pattern):表示反向否定断言。即该位置前面的字符不能匹配 pattern。
例如,(?<!95|98|NT|2000)Windows 能匹配 “3.1Windows” 中的 “Windows”,但不能匹配 “2000Windows” 中的 “Windows”。
注意,JS 中仅支持正向预查,不支持反向预查。
需要注意的是,这里特殊字符(
^ $ \b \B (?=p) (?!p))匹配到的是位置!!!其本质代表某一个位置。
分组与引用
正则表达式使用 () 来表示分组,即构成一个子表达式。
通过分组可以使得上面的 量词应用于多个字符,而非单个字符:
1 | /(abc){2}/ // 可以匹配:abcabc |
由于分组的这种特性,故其 不能放在字符簇([])中,但分组中 可以使用选择表达式:
1 | /(123|456){2}/ // 可以匹配:123123 或 456456 或 123456 或 456123 |
[1] >>> 捕获和非捕获分组
默认情况下,正则引擎在匹配过程中,会为每一个分组都开辟一个空间(用来捕获匹配到的文本),用来存储每一个分组匹配到的数据,以便于引用分组匹配的数据(捕获分组)。如下:
1 | > var regex = /(\d{4})-(\d{2})-(\d{2})/; |
你也可以通过在分组起始字符 (后,添加 ?: 让捕获分组变为非捕获分组 (?:pattern)。
非捕获分组不会开辟空间来捕获存储,示例如下(日期格式中的月、日不捕获):
1 | > var regex = /(\d{4})-(?:\d{2})-(?:\d{2})/; |
非捕获分组,可以起到性能优化的作用,节省了内存。
[2] >>> 捕获分组反向引用
使用捕获分组(默认)后,你可以在正则表达式分组之后,引用前面分组中捕获的数据( 捕获就是为了使用,否则就采用非捕获模式匹配,以优化性能)。
正则中,反向引用的语法是 >>> \number,即反斜杠(反向)加数字,其中数字表示引用前面第几个捕获分组。
例如,在匹配 HTML 标签时,为了使得 <xxx></xxx> 中后面的 xxx 能够和前面保持一致,你可以:
1 | /<([a-z]+)><\/\1>/ // 可以匹配:`<div></div>` 或 `<span></span>` 等双标签 |
正则可视化
为了更直观的查看正则表达式,推荐一个图形化展示工具 [ >>> RegulEx <<< ]。
正则表达式的基本语法,在任意编程语言中都是一样的。不同的是:每种编程语言会有自己独特的表现形式。
比如 JS 中用两个斜杠来包裹正则表达式的内容(/pattern/),而 Java 里没有这种写法;但是表达式里概念与写法是一样的。
运算符优先级
正则表达式计算遵循优先级顺序:相同优先级的从左到右进行运算,不同优先级的运算先高后低。
运算符优先级列表如下:
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 分组和字符簇 |
| *, +, ?, {n}, {n,}, {n,m} | 量词 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| |
选择表达式,取或 |
install_url to use ShareThis. Please set it in _config.yml.