Python 字符串之 Unicode 编码
Python 字符串也是一种数据类型,但是字符串比较特殊的是还有一个编码问题。Python2 中的字符编码是个老生常谈的话题,这一小节我们围绕字符串来看关于 Python2/Python3 中的字符编码问题。
开始 Pthon 字符串编码学习之前,请先了解:【编程基础之编码详解】,这是必要的。
Python 源文件的存储、编辑和执行
我们知道,磁盘上的文件都是以二进制字节码的格式存放的,也就是说 纯文本文件都是采用某种特定字符编码的字节形式存放的。
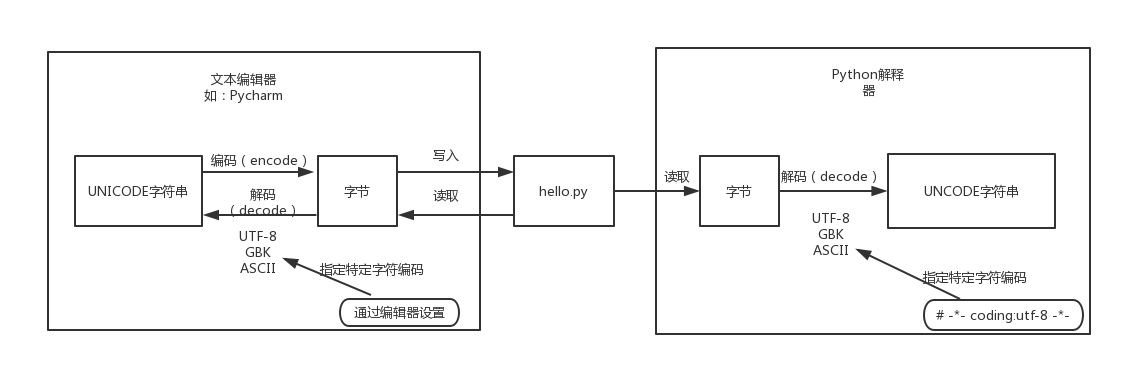
↓↓↓↓↓↓ 源文件的编辑和存储 ↓↓↓↓↓↓
对于程序源代码文件的字符编码是由编辑器指定的,比如我们使用 Pycharm 来编写 Python 程序时会指定工程中文件的编码为 UTF-8
那么 Python 代码被保存到磁盘时就会被转换为 UTF-8 编码对应的字节串(encode 过程)后写入磁盘。当重新编辑 Python 代码文件时,Pycharm 会从磁盘中读取文件的 UTF-8 字节串然后将其转换为 Unicode 字符串(decode 过程)到内存中进行修改。
↓↓↓↓↓↓ 源文件的执行 ↓↓↓↓↓↓
当执行 Python 代码文件中的代码时,Python 解释器在读取 Python 代码文件中的字节串之后,需要将其转换为 unicode 字符串(decode 过程)之后(内存中)才执行后续操作。
Python 默认编码机制
如果在源文件开始的部分(头部)没有明确指定字符编码,那么 Python 解释器会使用哪种字符编码进行解码呢?!!
Python 解释器提供了 “默认编码(Default Encoding)机制” ,来处理字节码。
Python2 的默认编码是 ASCII,故不能直接识别中文字符,需要显式指定字符编码;Python3 的默认编码 为 UTF-8,可以识别中文字符。
1 | # 通过 sys.getdefaultencoding() 来获取 Python 解释器中默认编码: |
| ================================================== Split Line =============================================== |
👇👇👇 UnicodeEncodeError 👇👇👇
广为人知的 “Python2 中文字符问题” 可以总结为一句话:当无法通过默认的字符编码对字节进行转换时,就会出现编码错误(UnicodeEncodeError)。
对于 Python2 来讲,Python 解释器在读取到中文字符的字节码尝试解码操作时,会先查看当前代码文件头部是否有指明当前代码文件中保存的字节码对应的字符编码是什么?!!
如果没有指定则使用默认字符编码 “ASCII” 进行解码导致解码失败,导致如下错误:
1 | SyntaxError: Non-ASCII character '\xc4' in file xxx.py on line 11, but no encoding declared; |
对于 Python3 来讲,执行过程是一样的,只是 Python3 的解释器以 “UTF-8” 作为默认编码,但是这并不表示可以完全兼容中文问题。比如我们在 Windows 上进行开发时,经常遇到 Python工程及代码文件使用 GBK 编码的情况,也就是说 Python 代码文件是被转换成 GBK 格式的字节码保存到磁盘中的。Python3 的解释器执行该代码文件时,试图用 UTF-8 进行解码操作时,同样会解码失败,导致如下错误:
1 | SyntaxError: Non-UTF-8 code starting with '\xc4' in file xxx.py on line 11, but no encoding declared; |
👇👇👇 Solution 👇👇👇
- 创建一个 Python 工程之后先确认该工程的默认字符编码规则是否已经设置为 UTF-8;
- 为了兼容 Python2 和 Python3,在代码头部声明字符编码:
# -*- coding:utf-8 -*-。
字符串和字节串
前面我们提到过:
Unicode 是逻辑意义上的编码,每个字符都有自己的 Unicode 码,在程序中可以通过 \uXXXX 的形式来表示,与字节流无关!!!
确实如此,Unicode 编码表示的才是真正的字符串,而用 ASCII、UTF-8、GBK 等字符编码表示的是字节串。
我们知道,字符是以字节的形式保存在文件中的。因此当我们在文件中定义的字符串被当做字节串也是可以理解的。但是,我们需要的是字符串,而不是字节串(是给计算机用来进行存储和传输的)。一个优秀的编程语言,应该严格区分两者的关系。
遗憾的是,很多编程语言试图混淆 “字符串” 和 “字节串”,他们把字节串当做字符串来使用,PHP、Python2 就属于这种编程语言。而在 Python3 中可能已经意识到之前的错误,重新进行了字符串的设计,所以开始明确的区分字符串与字节。
最能说明这个问题的操作就是 >>> 取一个包含中文字符的字符串的长度:
[1] –> Python 2
1 | # 字节串,长度为字节个数 = len('Hello,')+len('中国') = 6+2*2 = 10 |
可以发现,str 类型指代的是字节串,而经过 unicode 编码之后的才是字符串。所以要想 Python2 && Python3 兼容必须指定其编码方式为 # -*- coding:utf-8 -*-。
[2] –> Python 3
1 | str1 = 'Hello,中国' |
可以发现,已经可以明确字符串和字节串了。
字符串编码转换
结合上面我们提到过的解码编码,这一模块我们来看 Python 中的各种编码转换。
unicode 字符串可以与任意字符编码的字节进行相互转换,如图:
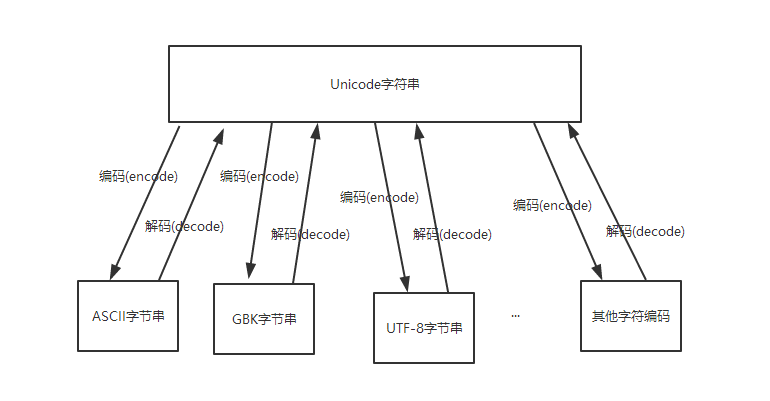
[1] –> Python2
首先,我们来简单看一下 Python2 中的字符串进行字符编码转换过程是:
[字节串] –> [decode(‘原来的字符编码’)] –> [Unicode 字符串] –> [encode(‘新的字符编码’)] –> [字节串]
1 | # -*- coding:utf-8 -*- |
[2] –> Python3
而 Python3 中定义的字符串默认就是 unicode,因此不需要先解码,可以直接编码成新的字符编码:
1 | # -*- coding:utf-8 -*- |
深入解析一下字节串
对于单个字符的编码,Python 提供了 ord() 函数获取字符的十进制编码值表示,chr() 函数把编码值转换为对应的字符:
1 | ord('A') |
获取字符串的字符 unicode 形式的表示 >>>>
- encode(‘unicode-escape’):可将此 str 编码为 bytes 类型, 内容则是 unicode 形式
- decode(‘unicode-escape’):可将内容为 unicode 形式的 bytes 类型转换为 str
1 | str = "中国" |
知道了字符串中字符的 unicode 编码,这里我们给出一个等价写法:
1 | str1 = "中文" |
再来看一下解码 >>>>
1 | b'ABC'.decode('ascii') |
如果 bytes(字节串)中包含无法解码的字节,decode()方法会报错:
1 | b'\xe4\xb8\xad\xff'.decode('utf-8') |
如果 bytes(字节串)中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
1 | b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore') |
可以看到,此时不再报错 UnicodeDecodeError,而是采用了忽略错误的做法。
Python 字符串之 Unicode 编码
https://www.orangeshare.cn/2018/01/05/python-zi-fu-chuan-zhi-unicode-bian-ma/
install_url to use ShareThis. Please set it in _config.yml.