Python 中的函数升阶
我们知道函数是 Python 内建支持的一种封装,通过一层一层的函数封装,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。本文作为 Python 中 函数使用的升阶内容。
前面已经介绍了 Python 函数的所有基本用法和使用注意事项,但是,Python 函数的用法还远不止此。
除了我们已经了解的函数赋值(别名)、局部函数、函数调用、函数间相互调用,甚至作为其他函数的返回值以外,Python 中还支持很多高级的用法:闭包函数、lambda 匿名函数、函数式编程等等。
lambda 匿名函数
Python 中支持一种快速定义简单函数的方法 –> Lambda 表达式,也称为匿名函数。
lambda 表达式,常用来表示内部仅包含 1 行表达式的简单函数。如果一个函数的函数体仅有 1 行表达式,则该函数就可以用 lambda 表达式来代替。
lambda 表达式的语法格式如下:
1 | name = lambda [list] : 表达式 |
其中,定义 lambda 表达式,必须使用 lambda 关键字;[list] 作为可选参数,等同于函数定义时指定的形参列表,name 为该 lambda 表达式(匿名含数)的名称。
明白为什么叫匿名函数了吗? >>>> 简单到不需要使用专门的函数名称,而是采用函数别名的方式直接赋值给变量就行了,就像一个表达式一样简单(lambda 表达式)。能猜到如何调用吗?:
1 | name() |
既然是等同于一个简单函数,故可以转换成普通函数的形式:
1 | def name(list): |
来一个实例(求 2 个数之和):
1 | # 求 2 个数之和的匿名函数 |
可以这样理解 lambda 表达式,其就是简单函数(函数体仅是单行的表达式)的简写版本。这可以帮助我们省去定义函数的过程,对于不需要多次复用的函数,使用 lambda 表达式可以在用完之后立即释放,提高程序执行的性能。
重新认识闭包函数
和前面讲的嵌套函数(局部函数)类似,不同之处在于,闭包中外部函数返回的不是一个具体的值,而是一个函数。
构成闭包的条件:
- 必须有一个内嵌函数(局部函数);
- 内嵌函数必须引用其外部函数中的变量;
- 外部函数的返回值必须是内嵌函数。
先来看一个例子(不定长参数的求和):
1 | def lazy_sum(*args): |
程序中,我们在函数 lazy_sum 中又定义了局部函数(内嵌函数) calc_sum,并且,内嵌函数 calc_sum 引用了外部函数 lazy_sum 的参数和局部变量。
当调用外部函数 lazy_sum 时返回 calc_sum 嵌入函数的引用,相关参数和变量都保存在返回的嵌入函数中,这就是一个典型的 “闭包(Closure)” 结构。
看到这里,读者可能会问,为什么要使用闭包呢?完全可以写成下面的形式(多简洁):
1 | def lazy_sum(*args): |
事实上,我们知道使用闭包结构,当外部函数结束后,其局部函数中使用到的外部函数相关联变量会被绑定到内部函数,这样你就可以使得这些变量始终保存在内存中,不会随外部函数的结束而清除,起到变量状态保存的作用。
基于此,你可以想到 >>>>
一般函数开头需要做一些额外工作,当需要多次调用该函数时,如果将那些额外工作的代码放在外部函数,就可以减少多次调用导致的不必要开销,提高程序的运行效率。
[1] >>>> 外部函数的每次调用返回都的是一个新的函数引用
这也就意味着,即使传入完全相同的参数:
1 | def lazy_sum(*args): |
f1() 和 f2() 的调用结果互不影响,可以看作每次执行内嵌函数调用都会新开辟一块内存空间。
[2] >>>> 内嵌函数被调用时才执行
使用闭包结构时,需要注意的是,外部函数调用时内嵌函数并没有立刻执行(用来返回来一个内嵌函数引用),而是直到显式调用内嵌函数 f1()/f2() 时才执行。
我们来看一个例子:
1 | def count(): |
上面程序中,每次循环都会向列表中添加一次内嵌函数引用(引用都不相同),然后最终把包含 3 个函数引用的列表返回。猜猜上面的代码结果是什么 –> 1, 4, 9 ?
但实际结果是:
1 | >> f1, f2, f3 : 9 9 9 |
f1, f2, f3 全部都是 9!!!
原因就在于(变量状态保存):尽管内嵌函数引用了外部函数的变量 i,但在调用外部函数时并非立刻执行,外部函数结束后返回了循环构建的 3 个函数引用列表,此时它们所引用的变量 i 已经变成了 3。之后使用 f1(), f2(), f3() 调用内嵌函数时,按照 i==3 计算,因此最终结果为 9。
牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
[3] >>>>闭包中循环变量的使用
如果一定要引用循环变量怎么办?
方法就是再内嵌函数外再外嵌套一个函数,用该函数的参数绑定循环变量当前的值,然后该参数的值会被绑定给内嵌函数,之后无论该循环变量后续如何更改,已绑定给内嵌函数参数的值不变:
1 | def count(): |
[4] >>>>闭包中的 closure 属性
闭包比普通的函数多了一个 __closure__ 属性,该属性记录着外部函数绑定给内嵌函数变量(自由变量)的地址。当闭包被调用时,系统就会根据该地址找到对应的变量,完成整体的函数调用。
以 outer() 为例,当其被调用时,可以通过 __closure__ 属性获取变量 b 存储的地址,例如:
1 | def outer(): |
可以看到,显示的内容是一个 int 整数类型,这就是 fun 中自由变量 b 的初始值。还可以看到,__closure__ 属性的类型是一个元组,这表明闭包可以支持多个自由变量的形式。
说是这么说的,得眼见为实(补充如下内容):
1 | print(fun.__closure__[0].cell_contents) |
Python 解释器 eval && exec
eval() 和 exec() 函数都属于 Python 的内置函数,功能相当于一个 Python 的解释器。
eval() 和 exec() 函数的功能都是可以 >>>> 执行一个字符串形式的 Python 代码(代码以字符串的形式提供)。
不同之处在于 >>>> eval() 执行完要返回结果,而 exec() 执行完不返回结果。
eval() && exec() 函数的语法格式为:
1 | # eval() |
可以看到,二者的语法格式除了函数名,其他都相同,其中各个参数的具体含义如下:
- expression:这个参数是一个字符串,代表要执行的语句 。该语句受后面两个字典类型参数
globals和locals的限制,只有在globals字典和locals字典作用域内的函数和变量才能被执行。 - globals:这个参数管控的是一个全局的命名空间,即
expression可以使用全局命名空间中的函数。如果只是提供了globals参数,而没有提供自定义的__builtins__,则系统会将当前环境中的__builtins__复制到自己提供的globals中,然后才会进行计算;如果连globals这个参数都没有被提供,则使用 Python 的全局命名空间。 - locals:这个参数管控的是一个局部的命名空间,和
globals类似,当它和globals中有重复或冲突时,以locals的为准。如果locals没有被提供,则默认为globals。
__builtins__是 Python 的内建模块,平时使用的 int、str、abs 都在这个模块中。通过 print(dic["__builtins__"]) 语句可以查看__builtins__所对应的value。
[1] >>>> globals 作用域
首先,通过如下的例子来演示参数 globals 作用域的作用,注意观察它是何时将 builtins 复制 globals 字典中去的:
1 | dic={} # 定义一个字典 |
运行结果为:
1 | dict_keys(['b']) |
上面的代码是在作用域 dic 下执行了一句 a = 4 的代码。可以看出,exec() 之前 dic 中的 key 只有一个 b。执行完 exec() 之后,系统在 dic 中生成了两个新的 key,分别是 a 和 __builtins__。其中,a 为执行语句生成的变量,系统将其放到指定的作用域字典里;__builtins__ 是系统加入的内置 key。
[2] >>>> locals 作用域
使用如下:
1 | a=10 |
[3] >>>> exec() && eval() 的区别
exec() && eval() 的区别在于:eval() 执行完会返回结果,而 exec() 执行完不返回结果。
实例演示:
1 | a = 1 |
运行结果为:
1 | 2 |
也就是说,exec() 中最适合放置运行后没有结果的语句,而 eval() 中适合放置有结果返回的语句。
[4] >>>> 应用场景
在使用 Python 开发服务端程序时,这两个函数应用得非常广泛。例如,客户端向服务端发送一段字符串代码,服务端无需关心具体的内容,直接跳过 eval() 或 exec() 来执行,这样的设计会使服务端与客户端的耦合度更低,系统更易扩展。
另外,如果读者以后接触 TensorFlow 框架,就会发现该框架中的静态图就是类似这个原理实现的:
- TensorFlow 中先将张量定义在一个静态图里,这就相当将键值对添加到字典里一样;
- TensorFlow 中通过 session 和张量的 eval() 函数来进行具体值的运算,就当于使用 eval() 函数进行具体值的运算一样。
需要注意的是,在使用 eval() 或是 exec() 来处理请求代码时,函数 eval() 和 exec() 常常会被黑客利用,成为可以执行系统级命令的入口点,进而来攻击网站。解决方法是:通过设置其命名空间里的可执行函数,来限制 eval() 和 exec() 的执行范围。
函数式编程
所谓函数式编程,是指代码中每一块都是不可变的,都由纯函数的形式组成。
认识函数式编程思想
纯函数构成? >>>> 是指函数本身相互独立、互不影响,对于 相同的输入,总会有相同的输出。
前面我们知道,既然变量可以指向函数,而函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数。函数式编程的一大特点 >>>> 即 允许把函数本身作为参数传入另一个函数,还允许返回一个函数(高阶函数)。
怎么理解呢???
先来看一个让列表中的元素值都变为原来的两倍的函数实现:
1 | def multiply_2(list): |
需要注意的是,这段代码不是一个纯函数的形式,因为列表中元素的值被改变了(“引用传递”),如果多次调用 multiply_2() 函数,那么每次得到的结果都不一样。
如何修改为纯函数的形式的实现呢? >>>>
1 | def multiply_2_pure(list): |
纯粹的函数式编程 >>>>
事实上,纯粹的函数式编程语言(比如 Scala),其编写的函数中是没有变量的,因此可以保证,只要输入是确定的,输出就是确定的;而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出。
对于 Python 而言,是允许使用变量的,所以它 并不是一门纯函数式编程语言。
Python 仅对函数式编程提供了部分支持,主要包括 map()、filter() 和 reduce() 这 3 个函数,它们通常都结合 lambda 匿名函数一起使用。接下来逐一介绍:
map()
map() 函数的功能是依次对可迭代对象中的每个元素,都调用指定的函数进行处理,并返回一个可迭代的(Iterable) map 对象。
map() 函数的基本语法格式如下:
1 | map(function, iterable) |
其中,function 参数表示要传入一个函数,其可以是内置函数、自定义函数或者 lambda 匿名函数;iterable 表示一个或多个可迭代对象,可以是列表、字符串、字典、集合、元组等。
需要注意的是,该函数返回的是一个
map对象,不能直接输出,可以通过for循环或者list()/tuple()等函数来显示。
实例演示一下 >>>>
比如我们有一个函数 f(x)=x*x,要把这个函数作用在一个 list [1, 2, 3, 4, 5, 6, 7, 8, 9] 上,使用 map() 实现原理图如下:
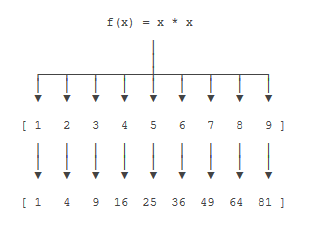
来看一下 Python map 实现:
1 | listDemo = [1, 2, 3, 4, 5, 6, 7, 8, 9] |
注意,map() 函数可传入多个可迭代对象作为参数 >>>>
1 | listDemo1 = [1, 2, 3, 4, 5] |
由于 map() 函数是直接由用 C 语言写的,运行时不需要通过 Python 解释器间接调用,并且内部做了诸多优化,所以相比其他方法,此方法的运行效率最高。
filter()
Python 内建的 filter() 函数可用于过滤序列。
filter() 函数的功能是对 iterable 中的每个元素,都使用 function 函数判断,然后根据返回值是 True 还是 False 决定保留还是丢弃该元素,最后将返回 True 的元素组成一个新的可遍历的 filter 对象。
filter() 函数的基本语法格式如下:
1 | filter(function, iterable) |
此格式中,funcition 参数表示要传入一个用于过滤的函数,iterable 表示一个待处理的可迭代对象。
【例 1】 list 中,删掉偶数,只保留奇数:
1 | listDemo = [0,1,2,3,4,5,6,7,8,9] |
【例 2】 把一个序列中的空字符串删掉:
1 | listDemo = ['A', '', 'B', None, 'C', ' '] |
可见用 filter() 这个高阶函数,关键在于正确实现一个 “筛选” 函数。
reduce()
reduce() 函数通常用来对一个集合做一些累积操作。其基本语法格式为:
1 | reduce(function, iterable) |
其中,function 规定必须是一个包含 2 个参数的函数;iterable 表示可迭代对象。
注意,reduce() 内置函数在 Python 3.x 中已经被移除,相应功能已放入了
functools模块。故使用前,需from functools import reduce导入 reduce。
如何理解 reduce() 要求 function 需要两个参数?怎样的累积操作? >>>>
reduce 把一个函数(必须接收两个参数)作用在一个序列 [x1, x2, x3, ...] 上,初始时 reduce 会从 iterable 中获取最开始的两个元素(x1 && x2)进行 function 处理(得结果 f_d_1),然后将结果(f_d_1)继续和下一个元素(x3)进行 function 处理(得结果 f_d_2),这就是累积过程,继续…..直至完成最后一个元素的累积,其效果就是:
1 | reduce(function, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4) |
–
【 例 1】 序列求和:
1 | from functools import reduce |
当然求和运算可以直接用 Python 内建函数 sum(),不适用 reduce(优先考虑)也可以。
【 例 2】 list(tuple) 序列转数字:
但是如果要把一个类似于 [1, 3, 5, 7, 9] 的序列变换成整数13579,reduce 就可以派上用场:
1 | from functools import reduce |
这个例子本身没多大用处,但是如果考虑到字符串 str 也是一个序列,对上面的例子稍加改动,配合 map(),我们就可以写出把 str 转换为 int 的函数:
【例 3】 数字字符串转数字(类似于 int(str) 一样的功能)
1 | from functools import reduce |
也就是说,假设 Python 没有提供 int() 函数,你完全可以自己写一个把字符串转化为整数的函数。
函数式编程小节
通常来说,当对集合中的元素进行一些操作时,如果操作非常简单,比如相加、累积这种,那么应该优先考虑使用 map()、filter()、reduce() 实现。另外,在数据量非常多的情况下(比如机器学习的应用),一般更倾向于函数式编程的表示,因为效率更高。
当然,在数据量不多的情况下,使用 for 循环等方式也可以。不过,如果要对集合中的元素做一些比较复杂的操作,考虑到代码的可读性,通常会使用 for 循环。
partial 偏函数
Python 的 functools 模块提供了很多有用的功能,其中一个就是偏函数(Partial function)。要注意,这里的偏函数和数学意义上的偏函数不一样。
简单的理解偏函数,它是对原始函数的二次封装,是将现有函数的部分参数预先绑定为指定值,从而得到一个新的函数,该函数就称为偏函数。
相比原函数,偏函数具有较少的可变参数,从而降低了函数调用的难度。
定义偏函数,需使用 partial 关键字(位于 functools 模块中),其语法格式如下:
1 | 偏函数名 = partial(func, *args, **kwargs) |
其中,func 指的是要封装的原函数,*args 和 **kwargs 分别用于接收无关键字实参和关键字实参。
【例 1】
1 | from functools import partial |
注意,当前偏函数调用时,必须采用关键字参数的形式给 age 形参传参,因为如果以无关键字参数的方式,该实参将试图传递给 name 形参,Python解释器会报 TypeError 错误。
结合以上示例不难分析出,偏函数的本质是将函数式编程、默认参数和冗余参数结合在一起,通过偏函数传入的参数调用关系,与正常函数的参数调用关系是一致的。
偏函数通过将任意数量(顺序)的参数,转化为另一个带有剩余参数的函数对象,从而实现了截取函数功能(偏向)的效果。在实际应用中,可以使用一个原函数,然后将其封装多个偏函数,在调用函数时全部调用偏函数,一定程序上可以提高程序的可读性。
sorted 内置排序函数
排序也是在程序中经常用到的算法。无论使用冒泡排序还是快速排序,排序的核心是比较两个元素的大小。
如果是数字,我们可以直接比较;但如果是字符串或者两个 dict 呢?直接比较数学上的大小是没有意义的,因此,比较的过程必须通过函数抽象出来。
[1] >>>> list(int)
我们前面提到过的,Python内置的 sorted() 函数就可以对 list 进行排序:
1 | sorted([36, 5, -12, 9, -21]) |
此外,sorted() 函数也是一个高阶函数,它还可以接收一个 key 函数来实现自定义的排序,例如按绝对值大小排序:
1 | sorted([36, 5, -12, 9, -21], key=abs) |
key 指定的函数将作用于 list 的每一个元素上,并根据 key 函数返回的结果进行排序。对比原始的 list 和经过 key=abs 处理过的 list:
1 | list = [36, 5, -12, 9, -21] |
然后 sorted() 函数按照 keys 进行排序,并按照对应关系返回 list 相应的元素。
[2] >>>> list(str)
我们再看一个字符串排序的例子:
1 | sorted(['bob', 'about', 'Zoo', 'Credit']) |
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面。
现在,我们提出排序应该忽略大小写,按照字母序排序。要实现这个算法,不必对现有代码大加改动,只要我们能用一个key函数把字符串映射为忽略大小写排序即可。忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写),再比较。
这样,我们给 sorted 传入key函数,即可实现忽略大小写的排序:
1 | sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower) |
要进行反向排序,不必改动 key 函数,可以传入第三个参数 reverse=True:
1 | >>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True) |
从上述例子可以看出,高阶函数的抽象能力是非常强大的,而且,核心代码可以保持得非常简洁。
用
sorted()排序的关键在于实现一个映射函数。
install_url to use ShareThis. Please set it in _config.yml.