编程入门有 Hello World,机器学习入门有 MNIST。本篇我们来看手写体数字图像数据集 MNIST 的获取和使用。
MNIST 是一个入门级的计算机视觉数据集,它包含各种手写体数字图片:
也包含每一张图片对应的标签信息,告诉我们这个是数字几。比如,上面这四张图片的标签分别是 5,0,4,1。
MNIST 下载使用说明 首先,来看如何下载 MNIST 数据集到本地???这里,我们提供两种下载方法:
手动下载 MNIST 数据集的官网:【 >>>> http://yann.lecun.com/exdb/mnist/ <<<< 】。
找到相应的下载链接即可下载,数据集如下:
脚本自动化安装 Tensorflow 团队对 MNIST 数据集进行了封装,为我们提供了一份用于 MNIST 数据集自动下载、安装,以及使用接口的 Python 源代码。
源代码参见:【 >>>> input_data.py <<<<】,脚本内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 """Functions for downloading and reading MNIST data.""" from __future__ import absolute_importfrom __future__ import divisionfrom __future__ import print_functionimport gzipimport osimport numpyfrom six.moves import urllibfrom six.moves import xrange SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/' def maybe_download (filename, work_directory ): """Download the data from Yann's website, unless it's already here.""" if not os.path.exists(work_directory): os.mkdir(work_directory) filepath = os.path.join(work_directory, filename) if not os.path.exists(filepath): filepath, _ = urllib.request.urlretrieve(SOURCE_URL + filename, filepath) statinfo = os.stat(filepath) print('Successfully downloaded' , filename, statinfo.st_size, 'bytes.' ) return filepath def _read32 (bytestream ): dt = numpy.dtype(numpy.uint32).newbyteorder('>' ) return numpy.frombuffer(bytestream.read(4 ), dtype=dt)[0 ] def extract_images (filename ): """Extract the images into a 4D uint8 numpy array [index, y, x, depth].""" print('Extracting' , filename) with gzip.open (filename) as bytestream: magic = _read32(bytestream) if magic != 2051 : raise ValueError( 'Invalid magic number %d in MNIST image file: %s' % (magic, filename)) num_images = _read32(bytestream) rows = _read32(bytestream) cols = _read32(bytestream) buf = bytestream.read(rows * cols * num_images) data = numpy.frombuffer(buf, dtype=numpy.uint8) data = data.reshape(num_images, rows, cols, 1 ) return data def dense_to_one_hot (labels_dense, num_classes=10 ): """Convert class labels from scalars to one-hot vectors.""" num_labels = labels_dense.shape[0 ] index_offset = numpy.arange(num_labels) * num_classes labels_one_hot = numpy.zeros((num_labels, num_classes)) labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1 return labels_one_hot def extract_labels (filename, one_hot=False ): """Extract the labels into a 1D uint8 numpy array [index].""" print('Extracting' , filename) with gzip.open (filename) as bytestream: magic = _read32(bytestream) if magic != 2049 : raise ValueError( 'Invalid magic number %d in MNIST label file: %s' % (magic, filename)) num_items = _read32(bytestream) buf = bytestream.read(num_items) labels = numpy.frombuffer(buf, dtype=numpy.uint8) if one_hot: return dense_to_one_hot(labels) return labels class DataSet (object def __init__ (self, images, labels, fake_data=False ): if fake_data: self._num_examples = 10000 else : assert images.shape[0 ] == labels.shape[0 ], ( "images.shape: %s labels.shape: %s" % (images.shape, labels.shape)) self._num_examples = images.shape[0 ] assert images.shape[3 ] == 1 images = images.reshape(images.shape[0 ], images.shape[1 ] * images.shape[2 ]) images = images.astype(numpy.float32) images = numpy.multiply(images, 1.0 / 255.0 ) self._images = images self._labels = labels self._epochs_completed = 0 self._index_in_epoch = 0 @property def images (self ): return self._images @property def labels (self ): return self._labels @property def num_examples (self ): return self._num_examples @property def epochs_completed (self ): return self._epochs_completed def next_batch (self, batch_size, fake_data=False ): """Return the next `batch_size` examples from this data set.""" if fake_data: fake_image = [1.0 for _ in xrange(784 )] fake_label = 0 return [fake_image for _ in xrange(batch_size)], [ fake_label for _ in xrange(batch_size)] start = self._index_in_epoch self._index_in_epoch += batch_size if self._index_in_epoch > self._num_examples: self._epochs_completed += 1 perm = numpy.arange(self._num_examples) numpy.random.shuffle(perm) self._images = self._images[perm] self._labels = self._labels[perm] start = 0 self._index_in_epoch = batch_size assert batch_size <= self._num_examples end = self._index_in_epoch return self._images[start:end], self._labels[start:end] def read_data_sets (train_dir, fake_data=False , one_hot=False ): class DataSets (object pass data_sets = DataSets() if fake_data: data_sets.train = DataSet([], [], fake_data=True ) data_sets.validation = DataSet([], [], fake_data=True ) data_sets.test = DataSet([], [], fake_data=True ) return data_sets TRAIN_IMAGES = 'train-images-idx3-ubyte.gz' TRAIN_LABELS = 'train-labels-idx1-ubyte.gz' TEST_IMAGES = 't10k-images-idx3-ubyte.gz' TEST_LABELS = 't10k-labels-idx1-ubyte.gz' VALIDATION_SIZE = 5000 local_file = maybe_download(TRAIN_IMAGES, train_dir) train_images = extract_images(local_file) local_file = maybe_download(TRAIN_LABELS, train_dir) train_labels = extract_labels(local_file, one_hot=one_hot) local_file = maybe_download(TEST_IMAGES, train_dir) test_images = extract_images(local_file) local_file = maybe_download(TEST_LABELS, train_dir) test_labels = extract_labels(local_file, one_hot=one_hot) validation_images = train_images[:VALIDATION_SIZE] validation_labels = train_labels[:VALIDATION_SIZE] train_images = train_images[VALIDATION_SIZE:] train_labels = train_labels[VALIDATION_SIZE:] data_sets.train = DataSet(train_images, train_labels) data_sets.validation = DataSet(validation_images, validation_labels) data_sets.test = DataSet(test_images, test_labels) return data_sets
使用时,直接通过下面的代码即可引入 TF 封装好的 MNIST 数据集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from tensorflow.examples.tutorials.mnist import input_dataMNIST_data_Path = "./MNIST_data/" mnist = input_data.read_data_sets(MNIST_data_Path, one_hot=True ) print("Training data size : " , mnist.train.num_examples) print("Validating data size : " , mnist.validation.num_examples) print("Testing data size : " , mnist.test.num_examples) print("Example training data(image): " , "\n" , mnist.train.images[0 ]) print("Example training data lable : " , mnist.train.labels[0 ])
可能由于网络原因导致 MNIST 数据集下载失败 <<<<【Network is unreachable】,你可以参考上一小节的手动下载,然后将下载好的数据集放置于相应路径中即可。
下载成功后,样例程序输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes . Extracting ./MNIST_data/train-images-idx3-ubyte.gz Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes . Extracting ./MNIST_data/train-labels-idx1-ubyte.gz Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes . Extracting ./MNIST_data/t10k-images-idx3-ubyte.gz Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes . Extracting ./MNIST_data/t10k-labels-idx1-ubyte.gz Training data size : 55000 Validating data size : 5000 Testing data size : 10000 Example training data : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. ................. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.34901962 0.9843138 0.9450981 0.3372549 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.01960784 0.8078432 0.96470594 0.6156863 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. ...................... 0. 0. 0. 0. 0.01568628 0.45882356 0.27058825 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ] Example training data lable : [0. 0. 0. 0. 0. 0. 0. 1. 0. 0. ]
👇👇👇 MNIST 数据集划分 👇👇👇
可以看出,input_data.read_data_sets 函数生成的数据集对象会自动将 MNIST 数据集划分为 train && validation && test 三个数据集。
其中,train 数据集中包含 55000 张训练图片,validation 数据集中包含 5000 张验证图片,它们共同构成了 MNIST 自身提供的训练数据集。test 数据集中包含了 10000 张测试图片,这些图片都来自于 MNIST 提供的测试数据集。
| ================================================== Split Line =============================================== |
👇👇👇 图像输入和标签处理 👇👇👇
FCNN 神经网络结构的输入是一个特征向量,所以这里需要将一张二维图像的像素矩阵扁平化处理为一维数组,方便 TF 将图片的像素矩阵提供给神经网络的输入层。
故,TF 封装模块处理后的每张手写数字图片都是一个长度为 784 的一维数组,这个数组中的元素对应了图片像素矩阵中的任意像素值(28 * 28 = 784)。为了方便计算,像素矩阵中像素的灰度值被归一化到 [0, 1],它代表了颜色的深浅。其中 0 表示白色背景(background),1 表示黑色前景(foreground)。
并且,对手写数字图片所对应的标签,进行了 one-hot 编码处理,方便神经网络的分类任务。one-hot 标签数组是一个 10 维(长度为 10)的向量,每一个维度都对应了 0~9 中数字中的一个。形如:[0,1,0,0,0,0,0,0,0,0] <<<< 数字 1。
| ================================================== Split Line =============================================== |
👇👇👇 Mini Batch 支持 👇👇👇
为了方便使用小批量样本梯度下降(MGD),input_data.read_data_sets 函数生成的数据集对象还提供了 mnist.train.next_batch 方法,可以快速从所有的训练数据中读取一小部分数据作为一个训练 batch。
以下代码显示如何使用这个功能:
1 2 3 4 5 6 7 BATCH_SIZE = 100 xs, ys = mnist.train.next_batch(BATCH_SIZE) print ('X Shape: ' , xs.shape) print ('Y Shape: ' , ys.shape)
该方法返回一个元组,其中包含了两个数组元素 <<<< 图片像素数组和标签数组,该元组可被用于当前的 TensorFlow 运算会话中。
你还可以直接将 input_data.py 脚本文件添加到你的项目中,解析或封装已经下载好的 MNIST 数据集:
1 2 import input_data mnist = input_data.read_data_sets("MNIST_data/" , one_hot=True )
需要注意脚本文件添加的目录,让其可以正常被 import 到。
你还可以基于上面的脚本文件进行修改,实现定制化的封装需要。
数据集可视化说明 MNIST(Mixed National Institute of Standards and Technology Database)是一个非常有名的手写体数字图像识别数据集(NIST 数据集的一个子集),也是一个入门级的计算机视觉数据集(很多资料会将其作为深度学习入门样例)。就好比编程入门有 Hello World,机器学习入门有 MNIST 。
MNIST 数据集中包含各种手写的数字图片:
MNIST 官方数据集可以分成两部分:
60000 行的训练数据集(mnist.train)10000 行的测试数据集(mnist.test)
其中,每一行 MNIST 数据单元(数据对象)由两部分组成:一张包含手写数字的图片,和手写数字图片所对应的标签。
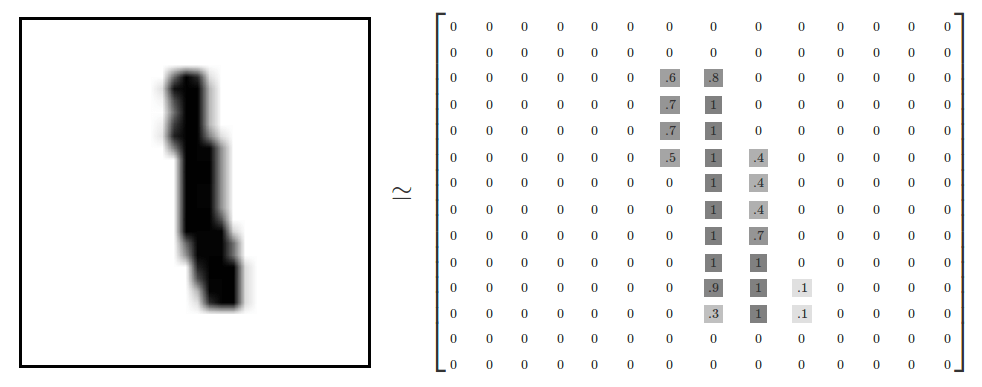
MNIST 数据单元 手写数字图像 >>>> 每一张图片都代表了一个手写的 0~9 中数字的灰度图(单通道图像),图片大小为 28 px × 28px。
我们可以用一个像素矩阵来表示手写数字 1 的图片:
关于图像的像素矩阵表示方法,可参考文档【 >>>> The Pixel Matrix Representation Of Image <<<<】。
图像标签 >>>> 每一个手写体数字图片,都对应 0~9 中的任意一个数字。
虽然 MNIST 数据集中只提供了训练数据(训练集)和测试数据(测试集),但是为了验证模型训练时的效果,使用时一般会从训练数据集中划分出一部分数据作为验证数据(集验证集)。
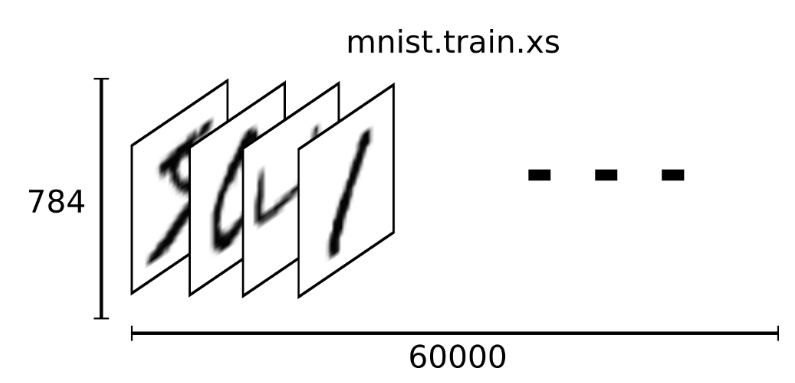
训练集可视化 这里,将通过可视化训练集来看看 TF 封装之后 MNIST 数据集究竟是什么样子的?!!验证集和测试集同训练集。
mnist.train.images 是一个形状为 [60000, 784] 的数组 >>>> 第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点数组。像素点的灰度值(强度值)被归一化到 0 和 1 之间。
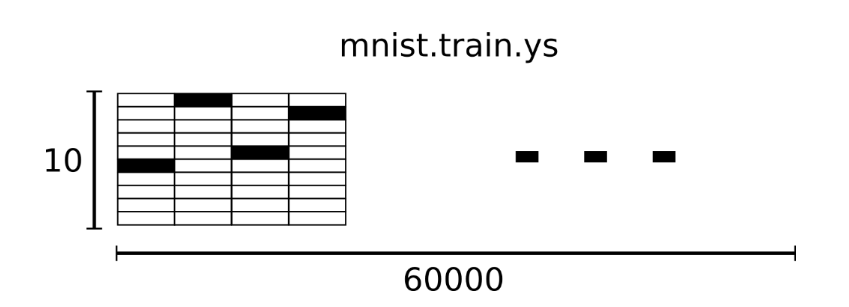
mnist.train.labels 是一个形状为 [60000, 10] 的数组,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的分类标签(one-hot vectors)。
在此张量里的每一个元素,都表示某张图片对应分类的 one-hot vectors 标签向量。比如,标签 0 将表示成([1,0,0,0,0,0,0,0,0,0,0])。
TF 引用样例 样例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 ''' Code For :MNIST 手写数字图像数据集使用 ''' import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_datadef main (arg=None ): ''' ## 初始化:下载或读取用于训练、测试以及验证的 MNIST 手写数字图片(28px * 28px)数据集 ## ''' MNIST_data_Path = "./MNIST_data/" mnist = input_data.read_data_sets(MNIST_data_Path, one_hot=True ) print("Training data size : " , mnist.train.num_examples) print("Validating data size : " , mnist.validation.num_examples) print("Testing data size : " , mnist.test.num_examples) if __name__ == '__main__' : tf.app.run()