TensorFlow GPU 支持: Ubuntu16.04 + Nvidia GTX + CUDA + CUDNN
Update:之前为了 TensorFlow 学习使用配置的 TensorFlow 深度学习环境(CPU Support)计算性能较差,已经不再适合现阶段学习开发使用了。故最近准备升级一下深度学习服务器,重新配置支持 GPU 显卡加速计算的 TensorFlow 深度学习开发环境。
配置过程中参考了网络上很多的相关博文,也遇到过很多坑,为了感谢配置过程中各位大佬的帮助以及方便本人下次配置或者升级,整理以作此文。
更多 TensorFlow 框架搭建相关内容,请关注博主相关博文系列 ↓↓↓↓↓
之一 >>>> 一文详解全平台 TensorFlow 深度学习框架在线搭建 (CPU&GPU 支持)
之二 >>>> TensorFlow GPU 支持: Ubuntu16.04 + Nvidia GTX + CUDA + CUDNN
Before Reading
TensorFlow GPU Support 配置须知:
服务器硬件要求
↓↓↓↓↓↓ 关于 内存(Memory)↓↓↓↓↓↓
16GB 以上。
推荐:条件允许,尽可能大一点。
↓↓↓↓↓↓ 关于 CPU ↓↓↓↓↓↓
不同于 TensorFlow For CPU Support 深度学习环境的搭建,GPU Support 环境主要使用 GPU 独立显卡进行计算加速,CPU 的核心数并不重要,只要拥有相对较高的主频就可以,因此对 CPU 的要求其实并不是很高。
推荐:具体根据实际情况进行选择,有条件的可以选择性能更好一点的,可以更好的兼容 TensorFlow For GPU Support 环境。
↓↓↓↓↓↓ 关于 GPU ↓↓↓↓↓↓
独立显卡是主角,TensorFlow For GPU Support 深度学习环境的核心计算都是依托于 GPU 进行运算的,故独立显卡的性能直接影响深度学习环境计算能力!!!
👇👇👇 并不是所有类型的独立显卡(GPU)都可以支持搭建 TensorFlow 深度学习环境 👇👇👇
我们需要能够 支持 CUDA 平台(一种由 NVIDIA 推出的通用并行计算架构)的 GPU 才行,故常见的深度学习独立显卡都选择【NVIDIA 显卡(也就是我们常说的 N 卡)】。
实际上,也并不是所有的 NVIDIA 显卡都支持此功能,NVIDIA 官方提供了 >>>> 【不同显卡系列的支持列表查询】 <<<< 同时你可以查看到相应 GPU 的计算能力。
如果你手头刚好有一块在支持列表内的独立显卡,那么恭喜你可以跳过本小节下面的内容开始后续的教程了~~~
| ============================================ 选购性价比 GPU? =============================================== |
如果你想要选购一块成本效益最佳的 GPU,推荐参考 Tim Dettmers 博客给出的 >>>> 【NVIDIA 卡分析与推荐–持续更新】 <<<< Tim Dettmers`s Experience and Advice for Using GPUs in Deep Learning。
这里给出博主测试出的主流显卡成本效益图,可供你参考选择:

本文我是基于手头现有的最好的设备进行搭建的,争取早日攒一台更好的服务器出来~~~
你应该了解你的 GPU
这里,你应该已经有了一块可以使用的 GPU 了。但在搭建基于 GPU 显卡加速运算的 TensorFlow【TensorFlow For GPU Support】深度学习环境之前,你首先应该做的就是:
先明确预使用的独立显卡(GPU )的详细信息(包括显卡型号、显存、计算性能等等)。
这是因为,TensorFlow 不仅对显卡类型(支持 CUDA)有要求,而且有些 TensorFlow 模型需要较大的 GPU 内存,或更多的 GPU 计算核心(即更强的计算能力,加速模型运算),了解预搭载独立显卡(GPU)的详细信息可以更好的帮助我们使用 GPU 进行 TensorFlow 计算加速。
CUDA && CUDNN && TF
TensorFlow 要想使用 GPU 进行计算加速(相较于 CPU),那么就必须部署 CUDA 和 CUDNN。
👇👇👇 先了解一下什么是 CUDA && CUDNN ? 👇👇👇
CUDA >>>> 显卡厂商 NVIDIA 推出的通用并行计算平台,它使得 GPU 能够解决并行的、复杂的计算问题。
CUDNN( cuDNN) >>>> CUDA DNN 的缩写,它是 CUDA 平台深度神经网络的计算库。想要在 CUDA 上运行深度神经网络,就要安装 cuDNN。
↓↓↓↓↓↓ 这里,需要注意一个问题(很重要)↓↓↓↓↓↓
我们知道 TensorFlow 提供有丰富的版本支持,但 某一版本的 TensorFlow 只兼容特定版本的 CUDA 和 CUDNN。也就是说,我们选择安装的显卡并行计算平台(CUDA)、深度神经网络 GPU 计算库(CUDNN)以及 TensorFlow 的版本要相互兼容。
↓↓↓↓↓↓ 关于 CUDA && CuDNN && TensorFlow 版本的选择问题 ↓↓↓↓↓↓
可以根据官方实测过的【Tensorflow && NVIDIA 版本信息对照表】进行选择,如下:
[1] >>>> For Linux/macOS >>>> 【TF CPU/GPU】
[2] >>>> For Windows >>>> 【TF CPU/GPU】
关于服务器操作系统选择
关于搭建 TensorFlow 深度学习开发环境的服务器(Server)的操作系统的选择,选择一个合适的 OS 可以帮我们减少很多的麻烦。
👇👇👇 Centos/Ubuntu Server Select 👇👇👇
| >>>> 1. Centos Server For Building TensorFlow ↓↓↓↓↓↓↓
如果选择 Centos Server,那么我们的 Centos 版本最好选择 Centos7。Centos6 因为版本较低,其操作系统内置的库无法很好兼容 TensorFlow。虽可以解决,但会为安装带来更多的麻烦(可以通过升级一些运行时库得以解决)。
当然对于操作系统为 Centos6 的既有服务器,且不可以更换操作系统的安装需求,TF-CPU 中已经对解决方法做详细说明。
| >>>> 2. Ubuntu Server For Building TensorFlow ↓↓↓↓↓↓↓
如果选择 Ubuntu Server(墙裂推荐),那么我们的 Ubuntu 版本最好是 Ubuntu 14.04/16.04/18.04。这里只是因为使用 Ubuntu14.04/16.04/18.04 的人较多,可以更好的帮我们解决安装以及使用 TensorFlow 过程中遇到的问题。
对于初学 TensorFlow 深度学习框架,仅仅想做做简单学习测试,强烈建议选择 Ubuntu!!!
👇👇👇 Windows Platform 👇👇👇
一般情况下,Windows 平台下搭建 TensorFlow 深度学习框架仅作为简单学习使用,无法更高效利用软硬件资源。故,我们更应该关注基于 Liunx Server 搭建学习、开发环境。
Environment Lists
基于以上,这里给出我的预安装环境准备:
[1] >>>> 硬件环境说明
- 搭载 Nvidia GeForce GTX 970 独立显卡联想 ThinkCentre 商业主机;
- 搭载 3TB 硬盘用于存储数据以及 32GB(4 * 8GB)内存条;
- 四核心 Inter CORE I7 CPU;
- ThinkCentre 商用主机。
–> 联想 ThinkCentre 商用主机搭载 Nvidia GTX 970 独立显卡时问题:
- 电源提供接口不够,购买电源转接线电源口 IDE 大 4D 芯一分二(4 pin公转母),显卡 6pin 转双大 4D。电源接线不够时,建议升级较大功率电源。
- 机箱主板空间较小无法安装索泰(ZOTAC)Nvidia GTX 970 独立显卡,购买 PCI-E 16X 显卡延长线。
- 购买 DVI 转 VGA24+5 Pin(显卡显示器高清视频转换接头)。
[2] >>>> 搭建环境说明
Ubuntu16.04 + Nvidia GeForce GTX 970 + CUDA8.0 + CUDNN5.1 + Tensorflow1.2.0
从这里开始,正式开始【TensorFlow GPU Support】深度学习环境的配置:
点亮 GPU && Ubuntu
首先,毋庸置疑的是可以成功点亮 >>>> 搭载了 GPU 独立显卡的 Ubuntu 服务器。
关于服务器操作系统,我们选择安装的是:Ubuntu16.04,具体的安装过程不赘述,网上有很多。
这里,有个需要注意的地方(很重要)>>>> 安装 Ubuntu16.04 系统时是否搭载(连接)GPU?!!
也就是说,这里我们有两种安装方式可供选择:
第一种:直接在主板上搭载 GPU,显示器接 GPU 输出接口,然后完成 Ubuntu16.04 系统的点亮;
第二种:不搭载 GPU(拔掉)安装好 Ubuntu16.04 系统(此时显示器接主机 VGA 接口),关机后安装好 GPU 并将显示器接 GPU 输出接口。
👇👇👇 重点来了 👇👇👇
通常使用的是第一种安装方式,但默认的前提是 Ubuntu16.04 安装引导系统能够正常识别 GPU(系统中默认显卡驱动支持该型号 GPU)。否则,你会发现:使用 U 盘启动盘安装系统时无法进入 Ubuntu 安装引导界面,怎么重启都没用。
而一旦拔掉 GPU,显示器转接主机 VGA 接口后,重启可成功进入安装引导界面(集显正常)。此时,你就需要考虑第二种方法了。
没看懂,不要着急~~~
故,搭建 TensorFlow [GPU Support] 环境第一步就是要解决系统显卡驱动问题:
显卡驱动
根据安装 Ubuntu16.04 系统时是否搭载(连接)GPU,分为两种显卡驱动安装方式:
[1] >>>> 搭载式安装 <<<< 对应上述第一种安装方式
[2] >>>> 非搭载式安装(推荐) <<<< 对应上述第二种安装方式
下面将针对上述两种安装方法,给出其显卡驱动安装的具体步骤。
查询系统显卡信息
首先,你需要查询当前系统显卡信息,以获取显卡详细信息,检查显卡驱动版本是否合适 CUDA 运算。具体检测过程如下:
1 >>>> 搭载式安装(第一种)
如果直接搭载 GPU 独显的服务器使用 U 盘启动安装 Ubuntu16.04,成功点亮了系统(显示器接 GPU 显示引导界面),那么恭喜你,当前系统默认显卡驱动支持你的 GPU。(如果无法成功,请移步至【2 >>>> 非搭载式安装(第二种) 】)
成功点亮系统后,我们可以直接查询当前系统中 GPU 的详细信息:
[1] >>>> 查询本机的显卡型号
因显卡一般接 PCI 接口,可以通过 lspci 查询显卡相关信息。一般我们可以查看到两种类型显卡:一块时集显;一块是独显。
1 | $ sudo lspci -vnn |grep VGA -A 12 |
| ================================= ↓↓↓↓↓ 显卡信息 ↓↓↓↓↓ ============================== |
独立显卡: 硬件厂商 NAVIDA(N卡);型号名称 GM206(GeForce GTX 970)
集成显卡:这里由于直接是搭载 GPU 的服务器安装系统,无法查看到集显信息
| ================================================================================ |
[2] >>>> 确认本机显卡驱动是否正常加载
1 | $ sudo lshw -C display |
输出信息 configuration 字段中,如果 driver=“驱动名称” 不为空,说明系统支持该显卡的驱动。
我们可以看出,Ubuntu 系统支持 GTX 970 显卡且自动安装有一个默认的显卡驱动:nouveau(Linux 开源的显卡驱动)。
事实上,nouveau 驱动开发是很不完善的,我们需要重新安装适合显卡的(这里是 GTX960) Nvidia 显卡驱动才可以正常使用 TensorFlow 深度学习显卡加速。
到这里,你可以直接跳转到【Nvidia 显卡驱动安装】小节,接着完成后续的过程。
2 >>>> 非搭载式安装(第二种)
如果你采用第一种直接搭载 GPU 独显的服务器使用 U 盘启动安装 Ubuntu16.04,发现:无法进入 Ubuntu 安装引导界面,怎么重启都没用。而一旦拔掉 GPU,显示器转接主机 VGA 接口后,重启可成功进入安装引导界面。
此时,我们首先需要先拔掉 GPU,后将显示器转接主机 VGA 接口,安装 Ubuntu16.04。
成功点亮系统后,我们可以查询当前系统中 GPU(集显)的详细信息:
[1] >>>> 查询本机的显卡型号
因显卡一般是 PCI 接口,可以通过 lspci 查询显卡相关信息。一般我们可以查看到两种类型显卡:一块时集显;一块是独显。
1 | deeplearning@ThinkCentre-M910s-N000:~$ lspci -vnn|grep VGA -A 12 |
这里只能查询到一块集显(未搭载独显):
| ================================= ↓↓↓↓↓ 显卡信息 ↓↓↓↓↓ ============================== |
集成显卡: 硬件厂商 Intel,型号名称 Corporation HD Graphics 630
| ================================================================================ |
[2] >>>> 确认本机显卡驱动是否正常加载
1 | deeplearning@ThinkCentre-M910s-N000:~$ sudo lshw -C display |
输出信息 configuration 字段中,如果 driver=“i915” 不为空,系统中集显驱动为:“i915”。
此时,先不要着急关机搭载 GPU!!!(如果你尝试关机后搭载 GPU,并将显示器接 GPU 输出接口同样会发现无法进入安装引导界面(系统中默认显卡驱动是不支持该型号 GPU的),故无法正常输出信号到显示器)。
↓↓↓↓↓↓ 解决办法 ↓↓↓↓↓↓
我们需要在安装好的系统中安装一个支持该型号 GPU 的先看驱动,接下文【Nvidia 显卡驱动安装】。
Nvidia 显卡驱动安装
下面我们来看,如何为特定型号的 GPU 安装合适版本的 Nvidia 显卡驱动:
1 >>>> 查询适合的 Nvidia 驱动
首先打开以及登陆 >>> Nvidia Driver 官网 <<< 根据独立显卡型号查询适合自己显卡的驱动(以 GTX 980 Ti 为例):
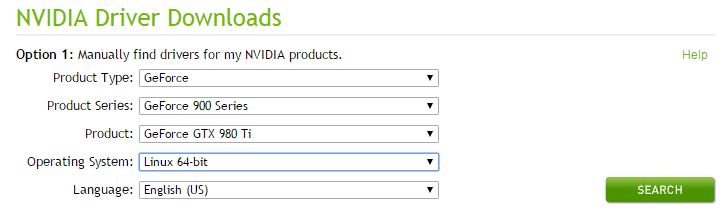
点击 SEARCH,查询显卡驱动信息:

2 >>>> 安装 Nvidia 驱动
查询到适用的 Nvidia 驱动版本后,开始安装 Nvidia 驱动 390.25:
[1] >>>> 使用 PPA 安装
↓↓↓↓↓↓ 1. 首先需要添加 ppa 仓库 ↓↓↓↓↓↓
1 | $ sudo add-apt-repository ppa:graphics-drivers/ppa |
第一次运行会出现如下的警告:
1 | Fresh drivers from upstream, currently shipping Nvidia. |
–>【Enter】后继续:
1 | # Enter 后显示如下信息表示添加成功: |
| ================================= ↓↓↓↓↓ 添加 PPA 仓库报错 ↓↓↓↓↓ ============================== |
如果添加 PPA 仓库报错的话,可以先 remove 掉,然后重新尝试:
1 | sudo add-apt-repository --remove ppa:graphics-drivers/ppa |
| ======================================================================================== |
↓↓↓↓↓↓ 2. 更新本地 apt-get 源 ↓↓↓↓↓↓
添加完 PPA 仓库,需要更新一下本地 apt-get 源,以检测添加的 PPA 仓库:
1 | $ sudo apt-get update |
↓↓↓↓↓↓ 3. 识别显卡模型和查看源中推荐的驱动程序 ↓↓↓↓↓↓
添加 PPA 仓库并且更新源后,先来识别显卡模型和查看源中推荐的驱动程序(如果采用非搭载式安装的话跳过):
1 | $ ubuntu-drivers devices |
为什么采用非搭载式安装的话跳过这里???非搭载式没有 GPU,查询无效,可直接选择【1 >>>> 查询适合的 Nvidia 驱动】中查询到的显卡驱动版本。
↓↓↓↓↓↓ 4. 安装源中推荐的驱动程序 ↓↓↓↓↓↓
首先你可以看到,PAA 仓库中提供有我们之前查询到的 390 版本的 Nvidia 驱动,你可以安装此版本。
当然,你也可以根据源中推荐的 Nvidia 版本进行安装(Recommended)。这里我的 GPU 为:GTX 970,故选择了 nvidia-384,它是支持 GTX 970 的一个稳定版本。
1 | $ sudo apt-get install nvidia-384 |
推荐阅读: 安装 Nvidia 驱动还有其它方法,但推荐使用 PPA 仓库安装 Nvidia 驱动,这是最简单的驱动安装方式。关于使用官方的驱动进行手动安装这里就不介绍了。
[2] >>>> 使显卡驱动生效
针对搭载式安装,直接重启:
1 | $ sudo reboot |
如果采用非搭载式安装的话,上述驱动安装完成后,直接关机,然后搭载 GPU 并将显示器接 GPU 输出接口,便可发现已经可以进入系统了。
| =============================================== Split Line ================================================== |
安装好显卡驱动后就可以进行驱动测试了:
[3] >>>> 确认安装的显卡驱动是否正常加载
1 | $ sudo lshw -C display |
可以发现,driver=nvidia 表明安装成功。
[4] >>>> 查看显卡运行状态
1 | $ watch -n -1 nvidia-smi |
Nvidia 驱动升级
对于已经安装了 Nvidia 显卡驱动的服务器,但其驱动版本过低。或者前面安装了不合适的 Nvidia 显卡驱动,无法正常使用新版本的 CUDA。
故,我们一般会将 Nvidia 显卡驱动更新到一个较新的版本。
前面我们已经知道如何安装全新的 Nvidia 显卡驱动,这里来看如何快速卸载服务器原有的显卡驱动程序:
1 | $ sudo apt-get --purge remove nvidia* |
上述我们已经卸载了系统中的 Nvidia 显卡驱动,注意 >>>> 此时千万不能重启,重新电脑可能会导致无法进入系统,安装好新驱动后再重启!
接下来我们需要根据章节【Nvidia 驱动驱动安装】完成新的 Nvidia 显卡驱动的安装。
Summary
好奇么?驱动安装不是都已经结束了,怎么还有一小节???黑脸?!!、
–> 总结一下:
前面我们知道了如何基于搭载 GPU 独显的服务器安装 Ubuntu16.04 ,然后安装适合版本的显卡驱动(搭载式)。
另外,我们还同时说明了非搭载式安装方法:先把 GPU 拿掉,然后在只有集显的服务器上先安装 Ubuntu16.04 ,接着按照章节【Nvidia 驱动驱动安装】安装 Nvidia 显卡驱动,然后 shutdown 关机安装上 GPU 后重启即可。
事实上,非搭载式安装方法可以帮助我们避免驱动安装中的很多麻烦。
👇👇👇 部署 CUDA && cuDNN 👇👇👇
在开始 CUDA 和 cuDNN 的部署之前,你需要通过查看 Tensorflow && NVIDIA 版本信息对照表 >>> 见【CUDA && CUDNN && TF】中说明,选择和预安装和 TensorFlow [GPU Support] 版本兼容的 CUDA && cuDNN 版本。
版本清单 >>>> TensorFlow v1.2.0 && CUDA Toolkit v8.0 && CuDNN v5.1。
部署 CUDA 8.0
我选择使用的 TensorFlow 版本是:TensorFlow-gpu-1.2.0,所以需要安装 CUDA 8.0。
在安装 CUDA 之前,Google 了一下,发现在 Ubuntu 下安装 CUDA 8.0 非常常见,支持 GTX 970。
下面我们将以 CUDA 8.0 的安装为样例(其它版本 CUDA 安装类似):
环境检测
安装 CUDA 8.0 之前,请先确认系统中是否已安装有默认的 CUDA 版本?!!执行如下命令查看系统 CUDA 版本:
1 | $ nvcc -V |
如果有,可以跳转至【CUDA 卸载】章节,先卸载掉系统中已安装的 CUDA 版本,再开始下面的步骤。
Download CUDA
下载 CUDA 需要注册和登陆 NVIDIA 开发者账号,CUDA8 下载页面提供了很详细的系统选择和安装说明。
这里,我们首先提供 >>> 【CUDA 8.0 下载地址】,并且选择做如下平台设置(其它版本戳 这里):
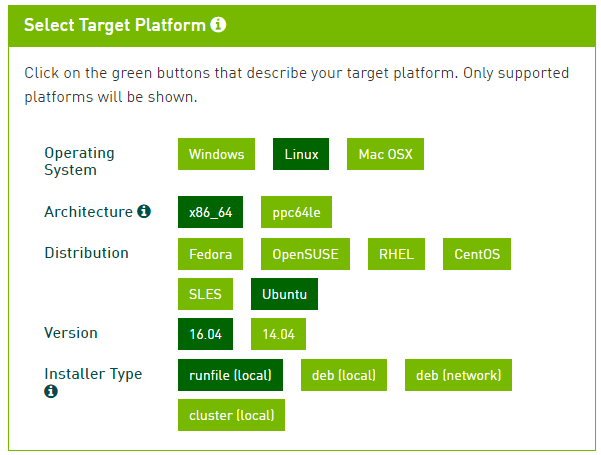
这里选择了 Ubuntu16.04 系统 Runfile 安装方案,千万不要选择 deb 方案,否则前方无数坑。
配置好平台设置后,进入下载界面。如下:
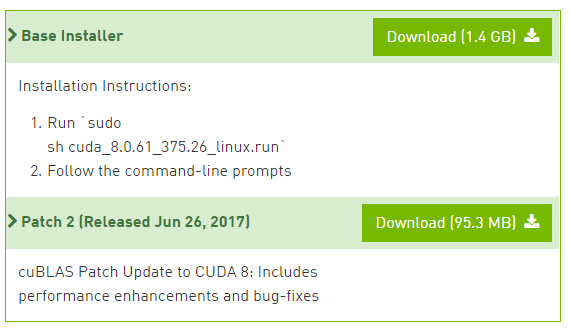
这里,只需下载 cuda_8.0.27_linux.run(1.4GB) 即可。
下载好的 cuda_8.0.27_linux.run 有 1.4G。下面按照 Nvidia 官方给出的方法安装 CUDA8:
Setup CUDA
1 | $ sudo sh cuda_8.0.27_linux.run --tmpdir=/opt/temp/ |
这里加了 --tmpdir 主要是因为直接运行 sudo sh cuda_8.0.27_linux.run 可能会提示空间不足的错误(如下)。实际上是全新的电脑主机,硬盘足够大的(当报错后,你知道如何解决即可)。
1 | Not enough space on parition mounted at /. |
–> 执行 sh cuda_8.0.27_linux.run 后会有一系列提示让你确认,非常非常非常关键的地方是是否安装 361 这个低版本的驱动:
1 | Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 361.62 ? |
答案必须是 n,否则之前为 GTX960 安装的 nvidia-384 驱动就白费了,而且后续问题多多。
👇👇👇 详细安装步骤如下 👇👇👇
1 | Logging to /opt/temp//cuda_install_6583.log |
安装完成之后,不要清空终端!不要清空终端!不要清空终端!后面有用处。
👇👇👇 配置环境变量 👇👇👇
安装完毕后,需要再声明一下环境变量,并将其写入到 ~/.bashrc 的尾部:
1 | export PATH=/usr/local/cuda-8.0/bin:$PATH |
更新 ~/.bashrc 配置文件:
1 | $ source ~/.bashrc |
注意:如果是已经安装了 NVIDIA 和 CUDA 的云服务器环境,还需要添加环境变量才可以使用。
| =============================================== Split Line ================================================== |
如果环境变量设置错误,导致 系统PATH 值被覆盖了,这会导致 ls、make 等基本命令都用不了,提示 xxx: command not found。后来查阅资料,通过输入以下语句,可还原 PATH 变量值进行恢复(恢复至默认 PATH 值):
1 | export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin |
至此,CUDA8.0 的部署其实已经完成了!!!但是请注意安装过程中这里可能有报错(missing recommended):
👇👇👇 Problem:Missing Recommended 👇👇👇
1 | Driver: Not Selected |
知道上面为什么不清空终端了吧~~~
不会报错,不注意的话,会导致后续 CUDA 测试( nbody 样例),如下:
1 | $ cd ~/NVIDIA_CUDA-8.0_Samples/5_Simulations/nbody |
即在 CUDA 上运行 nbody 样例,make 部分发生报错:
1 | >>> WARNING - libGLU.so not found, refer to CUDA Getting Started Guide for how to find and install them. <<< |
↓↓↓↓↓↓ 解决方案 ↓↓↓↓↓↓
从 make 报错信息中得知,缺少了一些编译库,下面我们来安装这些库文件:
1 | $ sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev libglfw3-dev libgles2-mesa-dev |
–> 成功之后会显示:
1 | > Windowed mode |
Test CUDA
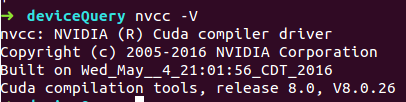
[1] >>>> 输出 CUDA 版本信息
1 | nvcc –V |
信息显示如下:
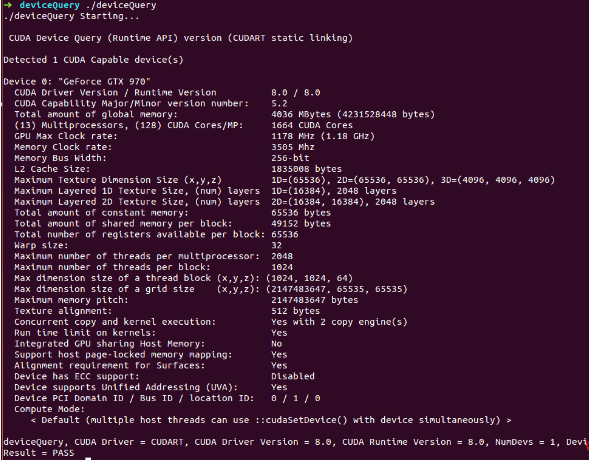
[2] >>>> 查询 GPU 信息
–> 进入 cd NVIDIA_CUDA-8.0_Sample/1_Utilities/deviceQuery 目录:
–> 执行:make;
–> 执行:./deviceQuery
结果如下:
[3] >>>> nbody 测试
nbody 测试见【Problem:Missing Recommended】中相关说明。
恭喜你~~~~ 至此,CUDA 部署已经完成!!!
Remove CUDA
通过前面的介绍,我们了解了如何在服务器上安装 CUDA 应用。事实上,很多时候我们的服务器本身已经默认安装了某个版本的 CUDA,而搭建 TensorFlow For GPU Support 环境要求安装特定版本的 CUDA。
如果你无法确认系统中是否存在使用当前版本 CUDA 的应用时,不推荐卸载,为了尽量降低对原始系统的影响,你可以跳转至【CUDA 多版本管理】来解决问题。
↓↓↓↓↓↓ 对于有卸载需求的,我们来看如何卸载服务器中已安装的 CUDA ↓↓↓↓↓↓
分别针对 .deb 和 .run 两种不同的安装方式(卸载方法不同),这里提供两种方式来卸载系统原有的 CUDA:
[1] >>>> .run 方法卸载
执行如下命令进行自动卸载(以 cuda-8.0 卸载为例):
1 | sudo /usr/local/cuda-8.0/bin/uninstall_cuda-8.0.pl |
有上述卸载文件 uninstall_cuda-8.0.pl 就说明是之前是用 .run 文件安装的,没有则是用 .deb 文件安装的,可以使用第二种方法进行卸载:
[2] >>>> .deb 方法卸载
1 | $ sudo apt-get remove cuda |
↓↓↓↓↓↓ 清空残留文件 ↓↓↓↓↓↓
最后,将当前目录切换至 /usr/local/ 下,查看是否还残留有未删除干净的 CUDA 相关文件:
1 | $ cd /usr/local/ |
接着来看 CUDNN 的下载与安装:
部署 CUDNN 5.1
CUDNN 全称 CUDA Deep Neural Network library,是 NVIDIA 专门针对深度神经网络设计的一套 GPU 计算加速库,被广泛用于各种深度学习框架,例如 Caffe, TensorFlow, Theano, Pytorch, CNTK 等。
Download CuDNN
从 Nvidia 官方 CuDNN 地址 下载链接选择一个期望版本,不过下载 cuDNN 前同样需要注册登录甚至填写一个简单的调查问卷,链接界面如下:

从中你可以选择适合操作系统的 CUDNN 计算加速库。
Setup CuDNN
安装 CuDNN 比较简单,解压后把相应的文件拷贝到对应的 CUDA 目录下即可:
1 | $ tar -zxvf cudnn-8.0-linux-x64-v5.1.tgz |
可以发现,cuDNN 中的 5 个文件(全部),在 /usr/local/cuda/include/ && /usr/local/cuda/lib64/ 中找不到相同文件:
1 | $ ls /usr/local/cuda/lib64/ |grep libcudnn |
也就意味着:CuDNN 其实就是 CUDA 的扩展计算库,把 cuDNN 相关库文件添加 CUDA 里,不会对 CUDA 造成其他影响,即所谓的 插入式设计。这保证了当前系统环境中可以存在多个版本的 cuDNN。
CuDNN 的插入式设计 >>>> 帮助我们简单、快捷的实现 CuDNN 的升级或多版本管理:
Update CuDNN
这里,假设一下:上面我们已经完成了 cuDNN v5.1 for CUDA8.0 的安装。事实上,我们需要的是 cuDNN v6.0 for CUDA8.0 计算加速包,那么我们如何将 cuDNN 版本升级到 cuDNN v6.0 呢???
其实很简单。下载 cuDNN v6.0 安装包 cudnn-8.0-linux-x64-v6.0.tgz、解压以及使用 cuDNN v6.0 库文件覆盖 CUDA 中的 cuDNN v5.1 库文件即可。详细步骤如下:
1 | tar -zxvf cudnn-8.0-linux-x64-v6.0.tgz |
至此,CUDA 8.0 以及 CUDNN 5.1 安装完成!!!接下来就可以开始 Tensorflow GPU Enabled 的安装了。
部署 TensorFlow-GPU
这里,我们使用 Anaconda 的方式来部署 TensorFlow-GPU 深度学习环境。
1 >>>> Conda Envs install TensorFlow
通过 Anaconda 安装 Tensorflow 详细过程参见博文 >>> 一文详解全平台 TensorFlow 深度学习框架在线搭建 (CPU&GPU 支持) <<< 【使用 Anaconda 安装】小节,篇幅原因不赘述。
对于其它方式的 TensorFlow 部署,可以参见博文中的其它章节。
2 >>>> TensorFlow 导入测试
正常情况,如果安装的 Python、TensorFlow、CUDA 、CUDNN 版本正确,import tensorflow as tf 时,无报错。
| ========================= ↓↓↓↓↓ CUDA & CUDNN 与不相容版本的 TensorFlow 问题 ↓↓↓↓↓ ========================= |
以安装 tensorflow-gpu1.3 为例:
1 | libcudnn.so.6:cannot open sharedobjectfile:No such file or directory |
根据错误代码,应该是找不到 libcudnn.so.6。
到指定文件夹下发现只有 5.0 和 8.0 的版本,没有 6.0,查找原因是因为当前已经是 1.3 版本,而 tensorflow-gpu1.3 已经开始去找 cudnn6 了(也就是说是用 cudnn6 编译的)…
故,需要换到 tensorflow-gpu1.2 版本,就解决问题了:
1 | 先卸载掉之前安装的错误版本的 TensorFlow 环境,然后重新安装 : |
| ================================================================================================== |
3 >>>> GPU 运算测试
这里以一个简单的向量加法为例来测试 TensorFlow [GPU Support] 环境,测试代码如下(gpu_test.py):
1 | import tensorflow as tf |
结果输出信息如下:
[3.1] >>>> 在没有 GPU 的机器上运行上述代码,可以得到如下输出:
1 | Device mapping: no known devices |
[3.2] 配置好 GPU 环境的 TensorFlow 中,没有明确制定运行设备的话,TensorFlow 会优先选择 GPU 设备运行,会得到如下结果:
1 | Device mapping: |
自此,我们就完成了 Ubuntu16.04 + Nvidia GTX 970 + CUDA8.0 + CUDNN + Anaconda3 + Tensorflow1.2 深度学习环境搭建。
You Need Know More
扩展阅读部分:
NVIDIA 显卡相关
[1] >>>> nvidia-smi
英伟达系统管理接口(NVIDIA System Management Interface, 简称 nvidia-smi),属于命令行管理组件,旨在帮助管理和监控 NVIDIA GPU 设备。
执行 nvidia-smi 命令可以查看当前系统安装的 NVIDIA 驱动信息以及 GPU 使用情况,显示如下:
1 | root@Ubuntu:~# nvidia-smi |
可以看出:驱动版本(NVIDIA-SMI 390.46)、显卡型号(Tesla P4)、内存(7611MiB:8G)以及 GPU 使用率(GPU-Util Compute M.: 0% Default)等。
nvidia-smi 配合 watch -n 一起使用,可用于查看 GPU 的实时动态使用情况:
1 | watch -n -1 nvidia-smi |
[2] >>>> lspci
查看服务器集成显卡信息:
1 | lspci | grep VGA |
查看服务器 NVIDIA 显卡信息:
1 | $ lspci | grep NVIDIA |
[3] >>>> 集显与独显的切换
NVIDIA 还提供了用于切换显卡的命令。例如,查看当前使用的显卡:
1 | sudo prime-select query |
如何切换 nvidia 显卡:
1 | sudo prime-select nvidia |
如何切换 intel 显卡:
1 | sudo prime-select intel |
CUDA 多版本管理
事实上,很多情况下我们需要多个 CUDA 版本兼容存在于服务器系统中,并且可以很容易地在不同版本之间进行迅速切换。
请参见如下场景:
场景一 >>> 多人共享使用当前服务器,由于使用的 TensorFlow 框架版本不同,所需要的 CUDA 版本也不同。此时,系统需要存在多个版本的 CUDA。
场景二 >>> 之前搭建 TensorFlow 环境使用的是 CUDA8.0 和 cuDNN5.1,当我们需要在 TensorFlow 环境中兼容其它深度学习环境时(比如搭建 TensorFlow + Pytorch 环境),Pytroch GPU Support 可能需要更高版本的 CUDA 以及 cuDNN。此时,升级 CUDA 以及 cuDNN 版本以适应 TensorFlow + Pytorch 环境是必要的。
怎么办???卸载重装???
这一章节,我们会以同时部署 cuda-8.0 和 cuda-9.0 版本为例进行说明:
CUDA 多版本共存
对于 cuda-8.0 和 cuda-9.0,无论先安装哪个版本,都一样。
上面已经安装过 cuda-8.0 了,这里,我们将扩展安装 cuda-9.0 版本:
1 >>>> Download && Setup CUDA9.0
下载 CUDA 需要注册和登陆 NVIDIA 开发者账号。这里,我们首先给出 >>> CUDA 版本库地址 <<< 供选择下载期望版本的 CUDA 安装包,版本库页面如下:

通过 CUDA 版本库地址进入 CUDA9.0 下载页面:

可以看到这里提供了很详细的系统选择和安装说明,这里选择了 Ubuntu16.04 系统 Runfile 安装方案(千万不要选择 deb 方案,否则前方无数坑)。
下载完成之后,进入到 CUDA9.0 安装包(cuda_9.0.176_384.81_linux.run)所在目录运行如下命令即可开始进行安装,详细安装过程讲解如下:
1 | sudo sh cuda_9.0.176_384.81_linux.run |
安装过程中是否创建 symbolic link 是关键。首次安装,选【yes】;安装额外的版本,选【no】。
2 >>>> 配置 CUDA 环境变量
在当前用户配置文件 ~/.bashrc 末尾添加如下内容:
1 | export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64 |
需要注意的是,这里配置的 CUDA 目录并不是特指 CUDA9.0 的安装目录,而是一个特殊的 CUDA 目录(不管 CUDA8.0/9.0/…)。这样做的好处你可以参见下一小节【CUDA 版本实时切换】。
自此,我们已经成功完成了 cuda-8.0 和 cuda-9.0 的安装。
下面我们来看如何迅速完成 CUDA 版本的切换:
CUDA 版本实时切换
通过上文可知,当我们安装了多个版本的 CUDA 之后,CUDA 一般会被安装到 /usr/local/ 目录(或你自己的自定义目录)下。查看一下当前目录下的文件:
1 | cd /usr/local |
上述 cuda-8.0 和 cuda-9.0 是系统中已安装的 CUDA 版本,而 cuda 就是我们上面创建的 symbolic link。
cuda指向系统当前正在启用的 CUDA 版本 >>> 方便了我们切换 CUDA 版本,可以让我们不用每次都去~/.bashrc修改环境变量的值(cuda-8.0/-9.0/...)。
我们先来查看当前 cuda 软链接指向的哪个 cuda 版本:
1 | stat cuda |
可以看到,cuda' -> '/usr/local/cuda-8.0,此时系统当前正在启用的 CUDA 版本为 cuda-8.0。
那么,我们如何快速完成 cuda-9.0 的版本呢?其实很简单:
1 | 1. 查看系统当前启用的 CUDA 版本: |
CUDNN 多版本管理
事实上,关于 CUDNN 多版本共存和实时切换的问题,在【部署 CUDNN 5.1】章节中 >>>> 【Update CuDNN】小节以及解决,请参考上文。
TensorFlow GPU 支持: Ubuntu16.04 + Nvidia GTX + CUDA + CUDNN
https://www.orangeshare.cn/2018/04/02/tensorflow-gpu-zhi-chi-ubuntu16-04-nvidia-gtx-cuda-cudnn/
install_url to use ShareThis. Please set it in _config.yml.