全流程解读网络爬虫通用编写流程,帮助你完成网络爬虫的快速入门指导!!!
编写爬虫脚本的通用流程如下:
通过 Python 网络模块(urllib/requests)发送 URL 请求以获取网页的 HTML 对象信息;
通过浏览器并借助网页元素审查工具分析网页结构以及元素节点信息;
根据网页结构以及元素节点信息,借助 HTML 对象解析工具(Regular Expression/Xpath/Beautiful Soup 4)以解析页面提取有效数据;
将提取到的有效数据持久化到本地磁盘(文件)或数据库。
下面将依照上述网络爬虫通用流程,逐布完善我们的网络爬虫脚本,最终已给出一个爬虫全流程示例。
请求获取网页 HTML 信息 首先来看,如何使用 Python 网络模块(urllib/requests)发送 URL 请求以获取网页的 HTML 信息?!!
以 Python 内置的 urllib 网络库为例 >>>
Use Built-in UrlLib Lib urllib 库属于 Python 的标准库内置模块,故安装 Python 后即可使用,无须单独安装。
Python 3 中,统一为 urllib 库,已经不存在 urllib2 库了。较低的 Python 2 中支持 urllib && urlib2 两个库来实现网络请求的发送。
urllib 库中包括了四个关键模块:
urllib.request 模块:用来发送 Request 以及获取 Request 的响应结果(Response);urllib.error 模块:定义了 urllib.request 模块可能产生的异常,你可以通过异常处理机制进行捕获处理;urllib.parse 模块:用来解析和处理 URL,例如 URL 编码以及解码;urllib.robotparser 模块:用来解析页面的 robots.txt 协议文件。
模拟发送请求 urllib.request 模块提供了基本的 HTTP Request 的构造方法,并且可以模拟发起一个浏览器的请求(Request)过程。
先来感受一下它的强大之处,以向百度(http://www.baidu.com/ )发起请求为例,获取百度首页的 HTML 信息:
1 2 3 4 5 6 7 8 9 import urllib.requestresponse = urllib.request.urlopen("http://www.baidu.com/" ) print(type (response))
输出结果如下:
1 <class 'http.client.HTTPResponse'>
可见,通过 urllib.request 模块的 urlopen(url) 方法向 URL 发送请求后,会返回一个百度首页的响应对象(HTTPResponse)。
已经获取到了网站的响应消息,如何通过响应消息对象获取我们需要的信息:
响应对象(HTTPResponse)重要属性与方法支持>>>>
1 2 3 4 5 6 7 8 9 10 11 12 response.getcode() response.read() response.getheaders() response.getheader(name) response.geturl() response.status response.msg response.version response.closed
示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 >>> import urllib.request>>> response = urllib.request.urlopen("https://www.baidu.com" )>>> print(response.geturl())http://www.baidu.com/ >>> print(response.getcode())200 >>> print(response.status)200 >>> print(response.getheaders())[('Server' , 'BWS/1.1' ), ('Date' , 'Fri, 30 Dec 2022 09:07:13 GMT' ), ('Content-Type' , 'text/html; charset=utf-8' ), ('Transfer-Encoding' , 'chunked' ), ('Connection' , 'close' ), ('Bdpagetype' , '1' ), ('Bdqid' , '0xf71f01670008eef5' ), ('P3p' , 'CP=" OTI DSP COR IVA OUR IND COM "' ), ('P3p' , 'CP=" OTI DSP COR IVA OUR IND COM "' ), ('Set-Cookie' , 'BAIDUID=A401074D3A894C1EF658A7E9ED45D774:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com' ), ('Set-Cookie' , 'BIDUPSID=A401074D3A894C1EF658A7E9ED45D774; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com' ), ('Set-Cookie' , 'PSTM=1672391233; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com' ), ('Set-Cookie' , 'BAIDUID=A401074D3A894C1EB80F6C57BCB052E4:FG=1; max-age=31536000; expires=Sat, 30-Dec-23 09:07:13 GMT; domain=.baidu.com; path=/; version=1; comment=bd' ), ('Set-Cookie' , 'BDSVRTM=0; path=/' ), ('Set-Cookie' , 'BD_HOME=1; path=/' ), ('Set-Cookie' , 'H_PS_PSSID=36558_37647_37906_36920_37990_37926_37901_26350_37957_37881; path=/; domain=.baidu.com' ), ('Traceid' , '1672391233035428020217806952993540075253' ), ('Vary' , 'Accept-Encoding' ), ('X-Frame-Options' , 'sameorigin' ), ('X-Ua-Compatible' , 'IE=Edge,chrome=1' )] >>> print(response.getheader("Server" ))BWS/1.1
上面,通过调用响应对象(HTTPResponse)的属性与方法,分别输出了:响应对象的 URL 地址、响应状态码、响应头信息,以及通过传递一个头部字段名称获取了 Server 的类型。
获取 HTML 信息 我们提到,通过响应对象(HTTPResponse)的 read() 方法可以获取到百度首页的 HTML 内容,即抓取到了网页的源代码,尝试一下:
1 2 3 4 5 6 7 >>> import urllib.request>>> response = urllib.request.urlopen("https://www.baidu.com" )>>> html = response.read().decode('utf-8' )>>> print(html)<!DOCTYPE html><!--STATUS OK--> <html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#2932e1"><meta name="description" content="全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到...">...</html>
可以看到,这里我们成功抓取到了百度首页的 HTML 源代码。那得到源代码之后呢??? >>> 我们想要的链接、图片地址、文本信息不就都可以提取出来了吗?!!
字节串解码 >>>>
需要注意的是,响应对象(HTTPResponse)的 read() 方法提取 HTML 信息,返回的数据是字节串类型(bytes)的。
为了将其转化为易于处理的字符串类型,故需要 对字节串进行解码操作 ,这就涉及到 Python 中常用的编码、解码操作:
1 2 3 4 5 6 7 string.encode("utf-8" ) bytes .decode("utf-8" )
由于 read() 方法返回的是采用 UTF-8 字符编码之后的字节串(bytes),故解码如下:
1 response.read().decode('utf-8' )
自此,我们已经基本完成了本节的目标:使用 Python 网络模块(urllib/requests)发送 URL 请求以获取网页的 HTML 信息。
URL 的编码和解码 我们知道,WEB 浏览器会通过 URL 发送一个请求,实现从相应的 Web 服务器请求特定的资源。
如果 URL 路径或者查询参数中,带有中文或者特殊字符的时候,浏览器在发送请求前会对 URL 进行 URL 编码,这是 URL 编码协议 规定的。
URL 编码协议中规定:URL 只允许使用 ASCII 字符集中可以显示的字符来通过因特网进行发送。
关于 URL 编码更详细的说明,请参见博文系列中 [ >>>> 网站基础之 URL 结构解析 <<<< ] 关于 URL 编码的说明。
以百度搜索查找关键词信息为例 >>>>
打开 百度首页 ,在搜索框中输入:爬虫 ,然后点击 “百度一下”。
当搜索结果显示后,此时地址栏的 URL 信息显示如下:
1 h ttps://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=爬虫&fenlei=256&rsv_pq=0xbf2a62e800111815&rsv_t=b88069xmyZzI8CzsTc9MHk9vLc%2Bpuy4NY0tyL6LdQx6z%2BCTKd1ZouF0Rn%2FFk&rqlang=en&rsv_enter=1&rsv_dl=tb&rsv_sug3=9&rsv_sug1=9&rsv_sug7=101&rsv_sug2=0&rsv_btype=i&inputT=1812&rsv_sug4=2982&rsv_sug=1
可以看到,URL 中包含了很多的查询字符串,你可以找到一个 wd=爬虫,其中 wd 表示查询字符串的键(word),而 爬虫 则代表你输入的值。
你可以在网页地址栏中删除多余的查询字符串,只保留 wd=爬虫,如下:
1 https://www.baidu.com/s?wd=爬虫
然后使用修改后的 URL 进行搜索,你会发现仍然得到了相同的页面。这是由于 wd 参数是 百度搜索的 关键查询参数 。
| >>> ============================================ Split Line ========================================= <<< |
接下来,使用上面 【 1.1.1 && 1.1.2 】小节介绍到的方法来抓取上述页面的 HTML 信息:
[1] >>> 编码 URL 查询字符串
在模拟发送请求前,你需要对 URL 中不符合 URL 编码协议的查询字符串进行编码处理。
urllib.parse 模块提供了 URL 的编码和解码方法,如下:
1 2 3 4 5 6 urllib.parse.urlencode({'key' :'value' }) urllib.parse.quote(string) urllib.parse.unquote(string)
注意 urlencode(dict) && quote(string) 方法的使用差异:
【示例一】 >>> urlencode
1 2 3 4 5 6 7 8 9 10 11 12 13 import urllib.parsequery_str = {"wd" : "爬虫" } res = urllib.parse.urlencode(query_str) url = "http://www.baidu.com/s?{}" .format (res) print(url)
编码后的完整 URL 如下:
1 http://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB
【示例二】 >>> quote(URL 编码后结果同上)
1 2 3 4 5 6 7 8 9 10 11 12 13 import urllib.parseword = "爬虫" res = urllib.parse.quote(word) url = "http://www.baidu.com/s?w={}" .format (res) print(url)
我们知道,经过浏览器编码处理之后的 URL 才是最终请求中的 URL,故通过编码后的 URL 必然也是可以访问相应的 Web 服务器的。你可以认为我们浏览器中通常可见的未编码处理的 URL 是给用户看的,而编码之后的 URL 是给设备使用的。
[2] >>> URL 地址拼接
上面我们使用了 Python 的 Format 格式化方法进行了 URL 地址的拼接,你还可以:
1 2 3 4 5 6 7 8 9 10 baseurl = 'http://www.baidu.com/s?' params = 'wd=%E7%88%AC%E8%99%AB' url = baseurl + params print(url) params = 'wd=%E7%88%AC%E8%99%AB' url = 'http://www.baidu.com/s?%s' % params print(url)
[3] >>> 模拟发送请求 && 获取 HTML 信息
准备好访问的 URL,就可以模拟发送,以及抓取目标页面的 HTML 信息了~~~
为了更好的使用 urllib 网络库编写爬虫,我们需要继续深入解读一下其中关键函数的用法:
深入解读 UrlLib 库 上面对 urlopen() 方法的简单使用,可以实现对简单页面的 GET 请求抓取。
如果我们想给 URL 传递一些隐式的参数该怎么实现呢(POST 请求)???
[1] >>> urllib.request.urlopen() 详解
先来看一下 urlopen() 函数的 API:
1 urllib.request.urlopen(url, data=None , [timeout, ]*, cafile=None , capath=None , cadefault=False , context=None )
可以发现,除了可以传递 URL 外,我们还可以传递其它的内容:比如 data(附加参数),timeout(超时时间)等等。
1)data 参数(可选)
data 参数,需要的是字节流编码格式的内容,即 bytes 类型。也就是说,需要将构建的附加参数转化为字节流才可传入。
并且需要注意的是,如果你传入了 data 参数,它的请求方式就不再是 GET 方式请求,而是 POST 。看如下示例:
1 2 3 4 5 6 7 8 9 10 from urllib import request, parseparams = {"word" : "hello" } data = bytes (parse.urlencode(params), encoding="utf-8" ) response = request.urlopen("http://httpbin.org/post" , data=data) print(response.read().decode("utf-8" ))
这里是通过向 HTTP 测试网站:httpbin.org ,发送 POST 请求来查看发送的请求和收到的响应信息。输出(请求)如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 { "args" : {}, "data" : "" , "files" : {}, "form" : { "word" : "hello" }, "Content-Length" : "10" , "Content-Type" : "application/x-www-form-urlencoded" , "Host" : "httpbin.org" , "User-Agent" : "Python-urllib/3.7" , "X-Amzn-Trace-Id" : "Root=1-63aeec25-63fa00987b2dca0168c5ef58" }, "json" : null, "origin" : "120.208.214.164" , "url" : "http://httpbin.org/post" }
可以看到,我们发送的附加参数出现在了 form 中,这表明是模拟了表单提交的方式,以 POST 方式传输数据。
注意:HTTP 测试网站 >>> httpbin.org ,能测试 HTTP 请求和响应的各种信息,比如 cookie、IP、headers 和登录验证等,且支持 GET、POST 等多种方法,对 Web 开发和测试很有帮助。
2)timeout 参数(可选)
timeout 参数可以设置请求的超时时间(单位为秒),支持 HTTP 、HTTPS 、FTP 请求。
如果请求超出了设置的这个时间还没有得到响应,就会抛出异常;如果不指定,就会使用全局默认时间。
来个实例感受一下:
1 2 3 4 from urllib import requestresponse = request.urlopen("http://httpbin.org/get" , timeout=0.1 ) print(response.read().decode("utf-8" ))
这里我们 请求了 http://httpbin.org/get 这个测试链接,并且设置了超时时间是 0.1 秒(基本不可能得到服务器响应),于是抛出一个超市异常:socket.timeout: timed out。
因此,你可以通过设置超时时间来控制一个网页如果长时间未响应就跳过它的抓取:
1 2 3 4 5 6 7 import urllib.requestimport sockettry : response = urllib.request.urlopen('http://httpbin.org/get' , timeout=0.1 ) except socket.timeout: print("Time Out !!!" )
或者,你可以捕获这个异常,做一些其它的处理。
3)其它参数
其中,context 参数,它必须是 ssl.SSLContext 类型,用来指定 SSL 设置。
cafile 和 capath两个参数是指定 CA 证书和它的路径,这个在请求 HTTPS 链接时会有用。
cadefault 参数现在已经弃用了,默认为 False。
[2] >>> urllib.request.Request() 详解
从上一小节可以看出,单纯使用 urlopen() 方法不足以构建一个完整的 HTTP 请求。
考虑一下,假设请求中需要添加请求头(Request Headers)等信息时,比如重构 User-Agent(用户代理,指用户使用的浏览器)使程序更像人类的请求,而非机器(反爬第一步)。怎么办???
我们可以使用更强大的 Request 类来构建一个请求,然后发送:
1 2 3 4 5 import urllib.requestrequest = urllib.request.Request("https://www.baidu.com" ) response = urllib.request.urlopen(request) print(response.getcode())
可以发现,我们依然使用 urlopen() 方法来发送这个请求,只不过这次 urlopen(url/Request) 方法的参数不再是一个 URL,而是一个 Request。通过构造这种数据结构(Request),一方面我们可以将请求独立成一个对象,另一方面可配置参数更加丰富和灵活 。
Request 类的构造方法:
1 class urllib .request .Request (url, data=None , headers={}, origin_req_host=None , unverifiable=False , method=None )
| >>> ============================================ 参数说明 ========================================= <<< |
url 参数(必备),其它参数可选。
data 参数同 urlopen 方法,必须传 bytes(字节流)类型的数据。如果添加参数是一个字典,可以先用 urllib.parse.urlencode() 编码为字符串,然后转化为字节串。
headers 参数是一个字典,你可以在构造 Request 时通过 headers 参数传递,也可以通过调用 Request 对象的 add_header() 方法来添加请求头。最常用的就是重构 User-Agent,默认的 User-Agent 是 Python-urllib(爬虫访问),你可以通过重构它来伪装成浏览器(而非爬虫),使程序更像人类的请求,而非机器。
origin_req_host 指的是请求方的 host 名称或者 IP 地址。
unverifiable 指的是这个请求是否是无法验证的,默认是 False。意思就是说用户没有足够权限来选择接收这个请求的结果。例如我们请求一个 HTML 文档中的图片,但是我们没有自动抓取图像的权限,这时 unverifiable 的值就是 True。
method 是一个字符串,它用来指示请求使用的方法,比如 “GET”,”POST”,”PUT” 等等。
| >>> ============================================================================================ <<< |
构建一个 Request 来感受一下其强大:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import urllib.requestimport urllib.parseurl = "http://httpbin.org/post" params = {"word" : "Spider" } data = bytes (urllib.parse.urlencode(params), encoding="utf-8" ) headers = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" , "host" : "httpbin.org" } req = urllib.request.Request(url=url, data=data, headers=headers, method="POST" ) response = urllib.request.urlopen(req, timeout=1 ) print(response.read().decode("utf-8" ))
运行结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 { "args" : {}, "data" : "" , "files" : {}, "form" : { "word" : "Spider" }, "headers" : { "Content-Length" : "11" , "Content-Type" : "application/x-www-form-urlencoded" , "Host" : "httpbin.org" , "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" , "X-Amzn-Trace-Id" : "Root=1-63af03d3-26062be47c618d2115808836" }, "json" : null, "origin" : "120.208.214.164" , "url" : "http://httpbin.org/post" }
可以看到,我们已经成功设置了 data,headers 以及 method。
另外,你也可以通过 Request 对象的 add_header(key, value) 方法来添加 headers:
1 2 req = urllib.request.Request(url=url, data=data, method="POST" ) req.add_header("User-Agent" , "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" )
[3] >>> urllib.request 高级特性
上面,我们虽然可以构造 Request 请求对象,但是一些更高级但常见的操作,如 authenticaton(授权验证),redirections(重定向)、Cookies、代理 IP 怎么设置???
这就需要更强大的工具 Handler 登场了~~~
简而言之,你可以把它理解为各种处理器(Handler):有专门处理登录验证的,有处理 Cookies 的,有处理代理设置的,利用它们我们几乎可以做到任何 HTTP 请求中所有的事情。
处理器(Handler)类说明 >>>>
首先需要说明下 urllib.request.BaseHandler,它是所有其他 Handler 的父类,提供了最基本的 Handler 的方法。
接下来就有各种 Handler 类继承这个 BaseHandler:
HTTPDefaultErrorHandler:用于处理 HTTP 响应错误的处理器(错误都会抛出 HTTPError 类型的异常);
HTTPRedirectHandler:用于处理重定向的处理器;
HTTPCookieProcessor:用于处理 Cookie 的处理器;
ProxyHandler:用于设置代理的处理器(默认代理为空);
HTTPPasswordMgr:用于管理密码的处理器,它维护了用户名密码的表;
HTTPBasicAuthHandler:用于管理认证的处理器,如果一个链接打开时需要认证,那么可以用它来解决认证问题。
其他的 Handler,可参考 >>> 官方文档 。
OpenerDirector 概念 >>>>
OpenerDirector 也叫 Opener。前面的 urllib.request.urlopen() 方法实际上就是一个 Opener。
为什么要引入 Opener 呢???
之前我们使用的 Request、urlopen() 相当于类库为你封装好了极其常用的请求方法,利用它们两个就可以完成基本的请求。但是现在我们需要实现更高级的功能,所以就要用到比调用 Request && urlopen() 的对象的更普遍的对象,也就是 Opener。
并且,Opener 可以使用 open() 方法,返回的类型和 urlopen() 如出一辙。
那么 Opener 和 Handler 有什么关系?简而言之,就是利用 Handler 来构建 Opener。
代理设置样例 >>>>
1 2 3 4 5 6 7 8 import urllib.requestproxy_handler = urllib.request.ProxyHandler({ 'http' : 'http://218.202.111.10:80' ,'https' : 'https://180.250.163.34:8888' }) opener = urllib.request.build_opener(proxy_handler) response = opener.open ('https://www.baidu.com' ) print(response.read())
上面,ProxyHandler 的参数是一个字典,key 是协议类型,比如 http 还是 https 等,value 是代理链接,可以添加多个代理。
然后利用 build_opener() 方法,利用 ProxyHandler 构造一个 Opener ,然后发送请求即可。
Cookie 设置样例 >>>>
如何将网站的 Cookie 获取下来:
1 2 3 4 5 6 7 8 9 10 import http.cookiejarimport urllib.requestcookie = http.cookiejar.CookieJar() handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open ('http://www.baidu.com' ) for item in cookie: print(item.name+"=" +item.value)
首先,声明了一个 CookieJar 对象,接下来使用 HTTPCookieProcessor 来构建一个 handler ,最后利用 build_opener 方法构建出 opener ,执行 open() 即可。
程序运行结果如下:
1 2 3 4 5 6 BAIDUID=552C3DCBEB1E5259021C3B13D89EFE9E:FG=1 BIDUPSID=552C3DCBEB1E5259DB7B1C021AEC02BD H_PS_PSSID=36548_37647_38024_38012_36921_37990_37793_37922_38000_37901_26350_37881 PSTM=1672418818 BDSVRTM=0 BD_HOME=1
可以看到输出了每一条 Cookie 的名称还有值。
不过既然能输出,那可不可以输出成文件格式呢???我们知道很多 Cookie 实际也是以文本形式保存的,实例:
1 2 3 4 5 6 7 8 9 10 11 12 import http.cookiejarimport urllib.requestfilename = 'cookie.txt' cookie = http.cookiejar.MozillaCookieJar(filename) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open ('http://www.baidu.com' ) cookie.save(ignore_discard=True , ignore_expires=True )
这时的 CookieJar 就需要换成 MozillaCookieJar ,生成文件时需要用到它,它是 CookieJar 的子类,可以用来处理 Cookie 和文件相关的事件,读取和保存 Cookie ,它可以将 Cookie 保存成 Mozilla 型的格式。
运行之后可以发现生成了一个 cookie.txt 文件,内容如下:
1 2 3 4 5 6 7 8 9 10 # Netscape HTTP Cookie File # http://curl.haxx.se/rfc/cookie_spec.html # This is a generated file! Do not edit. .baidu.com TRUE / FALSE 1703955537 BAIDUID 57210CFA95ED4AAE5E41CE04319F9861:FG=1 .baidu.com TRUE / FALSE 3819903184 BIDUPSID 57210CFA95ED4AAEE6DCD16048C7FA1B .baidu.com TRUE / FALSE H_PS_PSSID 36552_37647_37906_38014_37625_36920_37989_37936_37951_37903_26350_22158_37881 .baidu.com TRUE / FALSE 3819903184 PSTM 1672419537 www.baidu.com FALSE / FALSE BDSVRTM 0 www.baidu.com FALSE / FALSE BD_HOME 1
另外还有一个 LWPCookieJar,同样可以读取和保存 Cookie。但是保存的格式和 MozillaCookieJar 的不一样,它会保存成与libwww-perl的Set-Cookie3文件格式的 Cookie。使用时只需要在声明时就改为:
1 cookie = http.cookiejar.LWPCookieJar(filename)
生成文件内容如下:
1 2 3 4 5 6 7 #LWP-Cookies-2.0 Set-Cookie3: BAIDUID="E4A0DC4870957473807CD2478492DDD5:FG=1"; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2023-12-30 17:03:19Z"; comment=bd; version=0 Set-Cookie3: BIDUPSID=E4A0DC4870957473D133AD644C840120; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2091-01-17 20:17:26Z"; version=0 Set-Cookie3: H_PS_PSSID=36554_37647_38024_37907_38018_37623_36920_37990_37797_37927_37952_37904_26350_37881; path="/"; domain=".baidu.com"; path_spec; domain_dot; discard; version=0 Set-Cookie3: PSTM=1672419800; path="/"; domain=".baidu.com"; path_spec; domain_dot; expires="2091-01-17 20:17:26Z"; version=0 Set-Cookie3: BDSVRTM=0; path="/"; domain="www.baidu.com"; path_spec; discard; version=0 Set-Cookie3: BD_HOME=1; path="/"; domain="www.baidu.com"; path_spec; discard; version=0
既然生成了 Cookie 文件,怎样从文件读取并利用呢???
以 LWPCookieJar 格式为例:
1 2 3 4 5 6 7 8 9 10 11 import http.cookiejarimport urllib.requestcookie = http.cookiejar.LWPCookieJar() cookie.load('cookie.txt' , ignore_discard=True , ignore_expires=True ) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open ('http://www.baidu.com' ) print(response.status)
前提是我们首先利用上面的方式生成了 LWPCookieJar 格式的 Cookie ,然后利用 load() 方法,传入文件名称,后面同样的方法构建 handler 和 opener 即可。
| >>> ============================================== Split Line =========================================== <<< |
事实上,Python 内置的 urllib 网络库的使用较为 “繁琐”,不利于初学者的掌握。
后续,我们会引入一个第三方的,方便、快捷的 Requests 库,Requests 库是在 urllib 的基础上开发而来,其宗旨就是 “让 HTTP 服务于人类” 。
关于 Requests 库的使用说明可以参见博文系列中 [ >>>> Web Crawler 教程之网络爬虫工具库 <<<<] 中 Requests 网络库部分的说明。
↓↓↓↓↓↓↓ 反爬第一步 ↓↓↓↓↓↓↓
User-Agent User-Agent(UA)即用户代理,它是一个特殊字符串头部字段(headers)。
网站服务器,可以通过识别请求头中的 UA 来确定用户所使用的操作系统版本、CPU 类型、浏览器版本等信息,然后通过判断 UA 来给客户端发送不同的页面。
大多数网站,会通过识别请求头中 User-Agent 信息来判断是否是爬虫访问网站(Python-urllib )。例如,一旦检测到是爬虫在访问,会对发送请求的 IP 进行预警并重点监控,如果发现 IP 超过规定时间内的访问次数, 将在一段时间内禁止其再次访问网站(封 IP )。如果你在爬虫时登录了该网站,甚至会被封禁登录账户(封账户 )。
所以,你需要重构爬虫程序访问时的 User-Agent,这是必要的,这是反爬策略的第一步!!!
你可以,基于常见的浏览器 User-Agent 重构爬虫 UA >>>>
系统
浏览器
User-Agent字符串
Mac
Chrome
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36
Mac
Firefox
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0
Mac
Safari
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15
Windows
Edge
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763
Windows
IE
Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko
Windows
Chrome
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36
iOS
Chrome
Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_4 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) CriOS/31.0.1650.18 Mobile/11B554a Safari/8536.25
iOS
Safari
Mozilla/5.0 (iPhone; CPU iPhone OS 8_3 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12F70 Safari/600.1.4
Android
Chrome
Mozilla/5.0 (Linux; Android 4.2.1; M040 Build/JOP40D) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.59 Mobile Safari/537.36
Android
Webkit
Mozilla/5.0 (Linux; U; Android 4.4.4; zh-cn; M351 Build/KTU84P) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30
更多浏览器 UA 信息(移动端 && PC端)可参考 [ >>> 常见的浏览器 User-Agent <<< ]
如何查看本机的浏览器版本以及 UA 信息 >>>> [ >>> Browser Version && UA 在线识别工具 <<< ]
爬虫程序 UA 信息 你可以通过 HTTP 测试网站 >>> http://httpbin.org/ >>> 发送一个 GET 请求来获取请求头信息,从而获取爬虫程序的 UA 信息:
1 2 3 4 import urllib.requestresponse = urllib.request.urlopen("http://httpbin.org/get" ) print(response.read().decode("utf-8" ))
输出的请求头信息如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 { "args" : {}, # 请求头信息 "headers": { "Host": "httpbin.org", "User-Agent": "Python-urllib/3.7", # User-Agent 信息包含在请求头中 "X-Amzn-Trace-Id": "Root=1-63afe3f5-431e63ad6501f31a0c7aca33" }, "origin": "120.208.214.xxx", "url": "http://httpbin.org/get" }
可以看到,爬虫程序的 User-Agent 竟然是 Python-urllib/3.7 ,网站基于此会判断出是爬虫脚本在访问。
所以,我们需要重构爬虫程序访问时的 User-Agent,以伪装成 “浏览器” 访问网站:
重构爬虫 UA 信息 你可以使用 urllib.request 中的 Request 类来重构 User-Agent 信息:
1 2 3 4 5 6 7 8 9 10 11 12 import urllib.requesturl = "http://httpbin.org/get" headers = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36" } req = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(req) print(response.read().decode("utf-8" ))
输出的请求信息如下:
1 2 3 4 5 6 7 8 9 10 { "args" : {}, "headers" : { "Host" : "httpbin.org" , "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36" , "X-Amzn-Trace-Id" : "Root=1-63afed6e-65a5d0397ba0e73d1fbf3e1b" }, "origin" : "120.208.214.164" , "url" : "http://httpbin.org/get" }
可以看到,网站接收到的请求头信息中的 UA 信息已经变为伪装的 Chrome 浏览器 UA 了。
构建 UA 代理池 如果短时间内总是使用一个 UA 来高频率访问网站,可能会引起网站的警觉,认为是爬虫在访问,从而封禁 IP(账户)。
因此,我们需要构建用户代理池(User-Agent Pool),避免总是使用一个 UA 来访问网站。
用户代理池(User-Agent Pool),就是把多个浏览器的 UA 信息放入一个列表中,访问网站时从中随机选择一个浏览器 UA。
自定义 UA 代理池 >>>>
通过收集的浏览器 UA 来自定义一个 User-Agent Pool,然后随机获取 UA:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import randomua_pool = [ 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0' , 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11' , 'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11' , 'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1' , 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)' , 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50' , 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0' , 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1' , 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1' , 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1' ] ua_info = random.choice(ua_pool) print(ua_info)
除了上述的自定义用户代理池的方法,还有专门的第三方库支持随机获取浏览器 UA 信息(不用手动收集)。
随机产生 UA 的用户代理池第三方库 >>>> fake-useragent
由于 fake-useragent 库是一个第三方库,故需要单独按照:
1 pip install fake-useragent
安装成功之后,来看如何使用 fake-useragent 模块随机产生一个 UA:
1 2 3 4 5 6 7 8 9 10 11 import fake_useragentua = fake_useragent.UserAgent() print(ua.random)
如何产生指定浏览器的随机 UA >>>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import fake_useragentua = fake_useragent.UserAgent() print(ua.ie) print(ua.firefox) print(ua.chrome) print(ua.edge) print(ua.safari) print(ua.opera)
输入的不同浏览器的 UA 信息如下:
1 2 3 4 5 6 Mozilla/4.0 (compatible; MSIE 5.16; Mac_PowerPC) Mozilla/5.0 (X11; U; Linux i686; fr; rv:1.9.0.9) Gecko/2009042113 Ubuntu/8.04 (hardy) Firefox/3.0.9 Mozilla/6.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.0 (KHTML, like Gecko) Chrome/3.0.195.27 Safari/532.0 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17720 Mozilla/5.0 (Macintosh; U; PPC Mac OS X; fr) AppleWebKit/412.7 (KHTML, like Gecko) Safari/412.5 Opera/9.64 (X11; Linux i686; U; sv) Presto/2.1.1
实例:爬虫抓取网页信息 有了上面的知识储备,这里完成我们的第一个 Python 爬虫实战案例:抓取期望的网页信息,并将其保存至本地。
案例说明:抓取 百度搜索 关键词后检索到的首页信息 >>>>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import urllib.parseimport fake_useragentimport urllib.requestdef getUrl (word ): url = "http://www.baidu.com/s?{}" query_str = {"wd" : word} params = urllib.parse.urlencode(query_str) url = url.format (params) print("Request URL: " + url) return url def getUA (): ua = fake_useragent.UserAgent() return ua.edge def requestHtml (url ): ua_info = getUA() print("User-Agent: " + ua_info) headers = { "User-Agent" : ua_info, } req = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(req) print("Request Status Code:" , response.status) html = response.read().decode("utf-8" ) return html def dataSave (word, data ): filename = word + ".html" with open (filename, "w" , encoding="utf-8" ) as f: f.write(data) if __name__ == "__main__" : print("| >>>>>>>>>>>> Start Spider <<<<<<<<<<<< |" ) word = input ("Please Enter Your Search: " ) url = getUrl(word) html = requestHtml(url) dataSave(word, html) print("| >>>>>>>>>>>> Close Spider <<<<<<<<<<<< |" )
可以发现,通过百度搜索关键词后检索到的首页 HTML 代码都抓取了下来,并且保存在了被你的文件中。
需要注意的是,查看生成的网页信息文件时,你可能会发现抓取到的不是网页信息,响应内容显示 ….百度安全验证….网络不给力,请稍后重试….返回首页…问题反馈 。出现此问题可能是请求头定义不完善被反爬,详细请参见后文【网络爬虫常见问题】>>>【百度安全验证问题】。
审查网页结构以及元素节点信息 接着来看,如何通过浏览器并借助网页元素审查工具分析网页结构以及元素节点信息?!!
前面我们已经可以将网页中的所有信息(不管是否有用)都抓取下来了,为了提取出我们期望的信息,你必须先了解抓取网页文档的结构以及元素节点信息!!!
网页的构成 根据 W3C 标准模式,网页一般由三部分组成:
HTML:负责定义网页的内容;
CSS:负责描述网页的样式;
JavaScript:负责网页的行为。
网页构成是爬虫的基础,关于 HTML && CSS && JavaScript 的详细说明可以参考相关博文系列。
动态网页 VS 静态网页 实际上,在编写爬虫之前,你首先需要 明确待爬取页面的类型:页面是静态的,还是动态的???
这是由于,对于不同的网页类型,编写爬虫程序时所使用的方法也不尽相同。
| >>> ============================================= Split Line ========================================== <<< |
静态网页 静态网页是网站设计的基础,早期的网站一般都是由静态网页制作的。
纯粹 HTML 格式的网页通常被称为 “静态网页”,静态网页是标准的 HTML 文件,它的文件扩展名是 .htm Or .html,可以包含文本、图像、声音、FLASH 动画、客户端脚本和 ActiveX 控件等。
容易误解的是>>>> 静态并非静止不动 ,页面中也可以出现各种动态的效果,如 GIF 动画、FLASH、滚动字幕等等,这只是一种网页内容的表现形式。
我们知道,当页面所包含的信息量较大时,网页的生成速度会降低。而由于 静态网页的内容相对固定,且不需要连接后台数据库,因此响应速度非常快。 但静态网页的更新相较比较麻烦,需要将所有的更新内容添加的页面中,故一般适用于更新较少的展示型网站。
静态页面抓取 >>>
静态网页可以通过 GET/POST 请求方法直接获取,它的数据全部包含在 GET/POST 请求返回的 HTML 文档中,因此爬虫程序可以直接在返回的 HTML 文档中提取数据。
也就是说,只要通过分析静态网页的 URL,找到 URL 查询参数的变化规律之后,就可以实现静态页面的抓取了。
与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎的收录。
动态网页 动态网页,指的是采用了动态网页技术的页面,例如:AJAX(是指一种创建交互式、快速动态网页应用的网页开发技术)、ASP(是一种创建动态交互式网页并建立强大的 web 应用程序)、JSP(是 Java 语言创建动态网页的技术标准) 等技术。
动态网页中,不需要重新加载整个页面内容,就可以实现网页的局部更新。
也就是说,动态页面使用 “动态页面技术” 与服务器进行数据交换,从而实现了网页的异步加载。
动态页面技术 >>>
实际上,你可以将 动态页面技术 理解为:页面中除了 HTML 标记语言外的一些具有特定功能的代码。
这些代码,可以使得浏览器和服务器进行交互,服务器端会根据客户端的不同请求,执行可能涉及到数据库连接、访问、查询等一系列的 IO 操作(响应速度略差于静态网页),然后返回请求信息给浏览器,从而实现网页的异步加载。
以查看百度图片为例 >>>
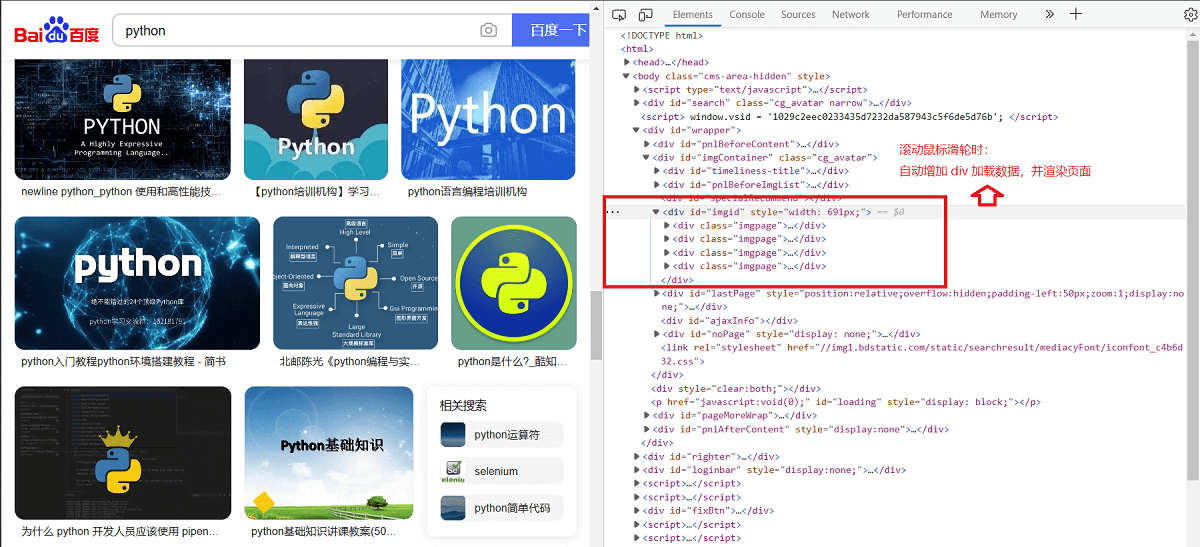
浏览器中打开百度图片(https://image.baidu.com/ )并搜索 Python,向下滚动鼠标滑轮,会查看到越来越多的逐渐加载出来的图片。
也就意味着,当你滚动鼠标滑轮时,网页会从服务器数据库自动加载数据并渲染页面。如下所示:
动态页面抓取 >>>
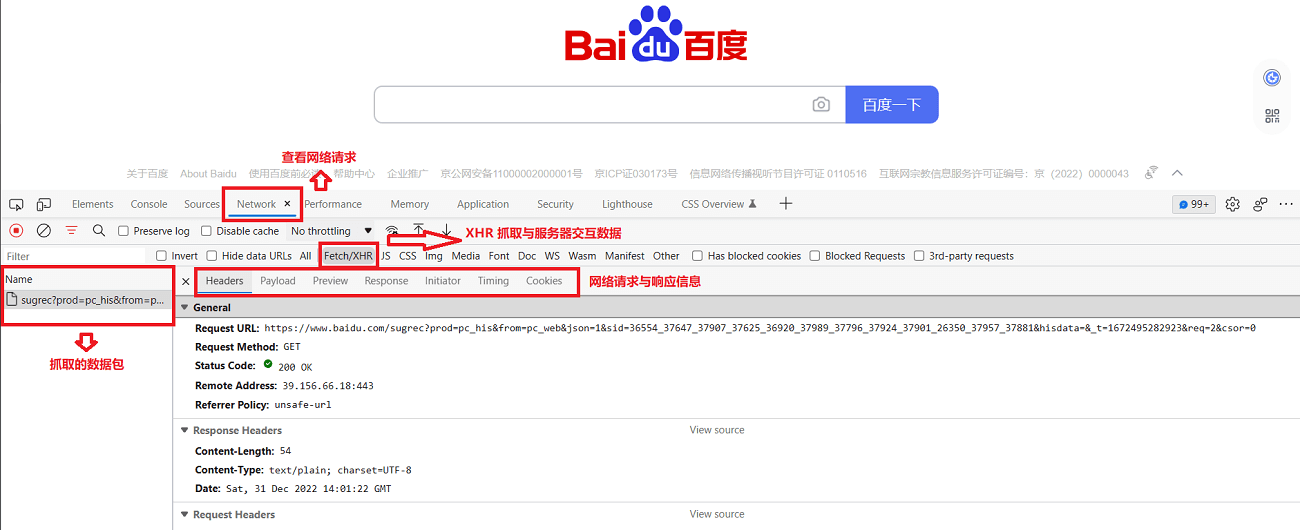
抓取动态网页的过程较为复杂,需要通过动态抓包来获取客户端与服务器交互的 JSON 数据。
抓包可以使用谷歌浏览器开发者模式(快捷键:F12)Network 选项,然后点击 XHR,找到获取 JSON 数据的 URL,如下所示:
或者,你也可以使用专业的抓包工具 >>>> Fiddler 。
审查页面元素 对于一个优秀的爬虫工程师而言,要善于发现 HTML 网页元素的规律,并且能从中提炼出有效的信息。
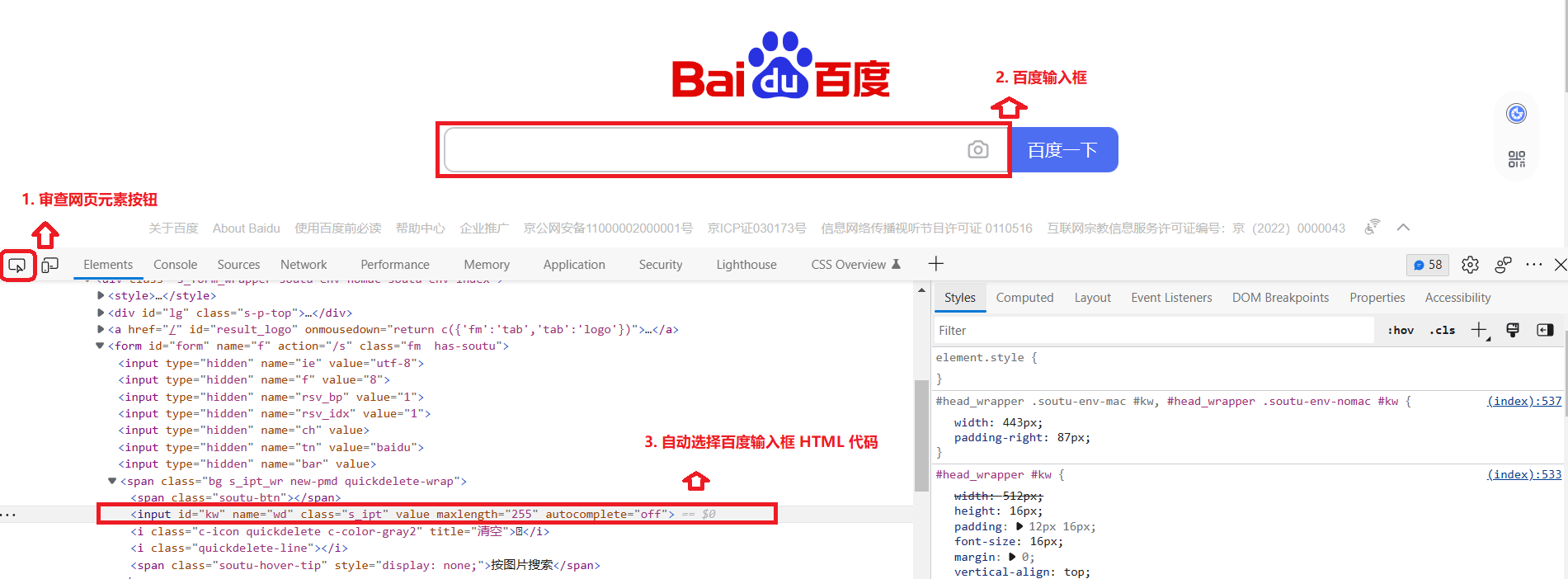
浏览器都自带审查页面元素(Inspect)的功能,你可以通过打开浏览器的开发者工具(F12),审查页面元素功能在页面的左上角,如图:
通过审查页面元素(Inspect)功能,你可以确定网页中某内容所对应的 HTML 代码位置。下图以 百度首页中搜索框 为例:
点击审查元素按钮 >>> 将鼠标移动至想审查的位置(如:百度的输入框),然后单击 >>> 自动显示该位置内容的代码段(如上图)。
并且,代码段处支持快速复制 >>> 右击代码段 >>> Copy 选项卡 >>> 二级会话框内选择 Copy element。即可复制正在审查的元素代码,如下:
1 <input id ="kw" name ="wd" class ="s_ipt" value ="" maxlength ="255" autocomplete ="off" >
依照上述方法,你可以检查页面内的所有元素。
编辑网页代码 >>>>
通过元素审查,你可以快速定位到页面内容的元素代码段。然后你可以基于定位代码段,更改网页代码。
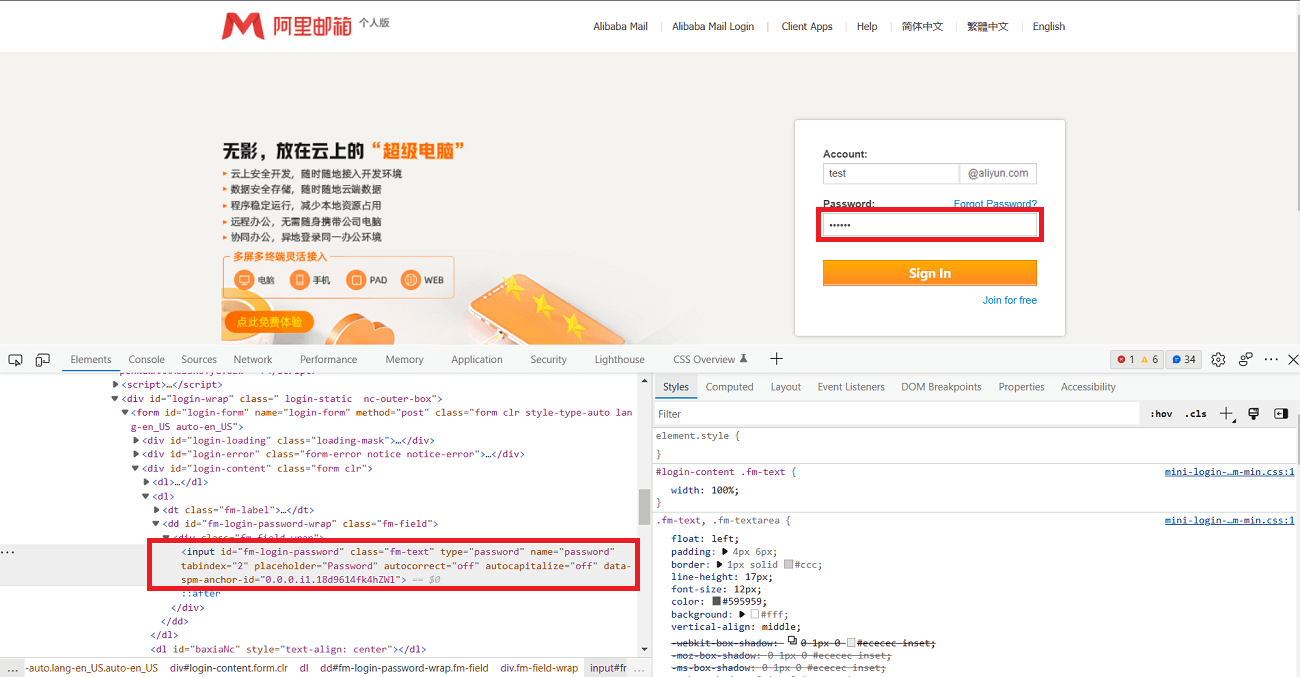
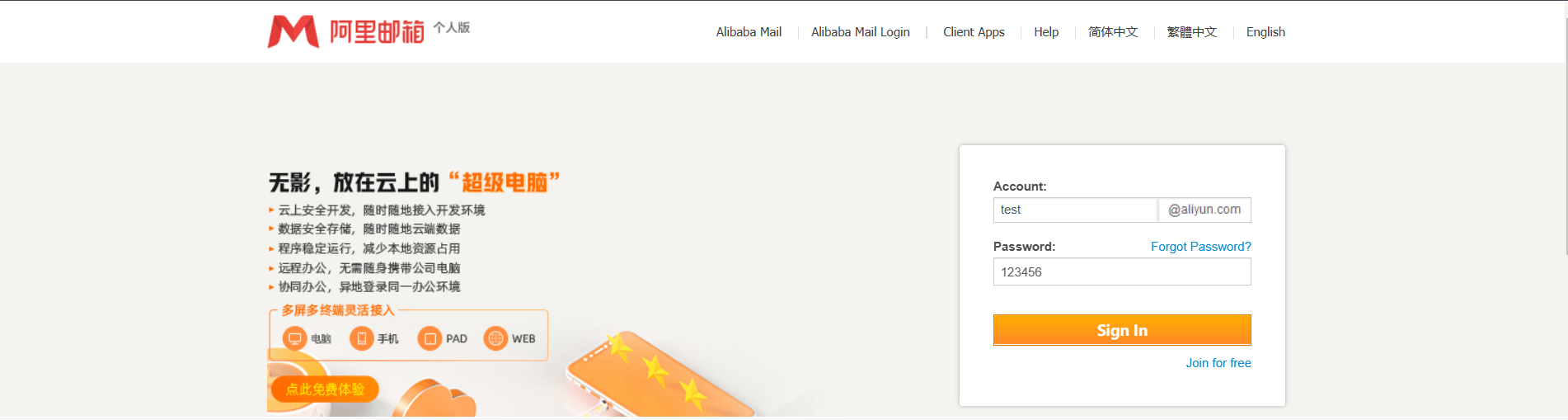
以 阿里云个人邮箱登录界面 为例:
检查密码框的 HTML 代码,代码如下所示:
1 <input id ="fm-login-password" class ="fm-text" type ="password" name ="password" tabindex ="2" placeholder ="Password" autocorrect ="off" autocapitalize ="off" data-spm-anchor-id ="0.0.0.i1.18d9614fk4hZWl" >
你只需要在代码段上稍微做一下更改(双击 type="password" 将输入框类型更改为 type="text"),密码就会变为可见状态。效果如下:
此操作适用于所有网站的登录界面!!!
需要注意的是,更改网页代码效果仅限本次有效,当关闭(或重新刷新)网页后,会自动恢复为原来的状态。
检查网页结构 对于网络爬虫而言,检查网页结构是至关重要的一步。
检查网页结构,即 对网页的 HTML 文档结构进行分析,并找出要提取信息所对应元素节点的相似性(规律)。
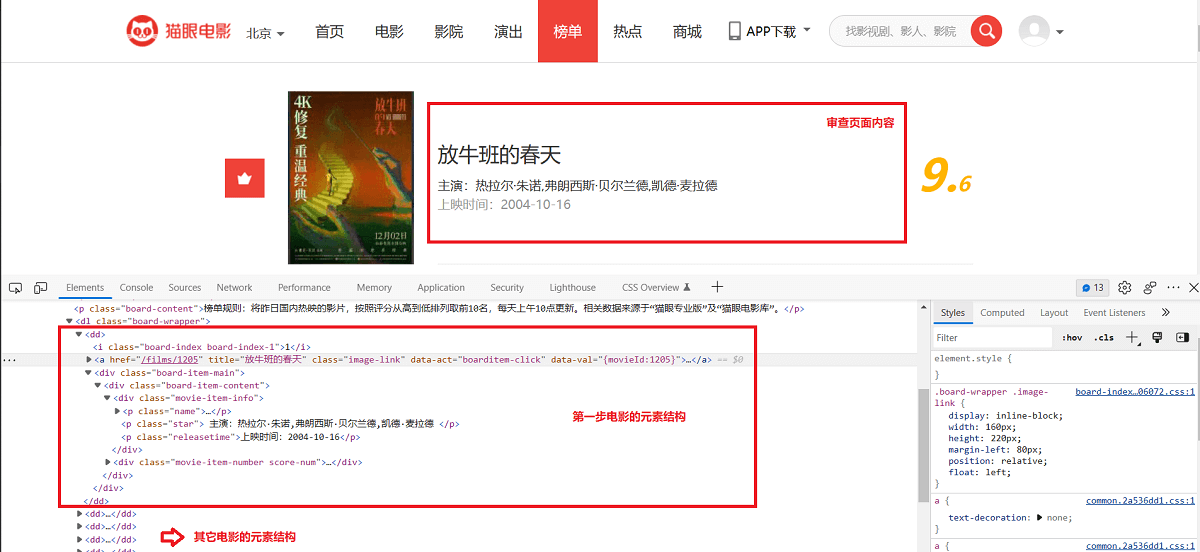
以 猫眼电影网 榜单页面为例(期望提取榜单中电影信息),审查每部影片的 HTML 元素结构:
第一部影片的代码段如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <div class ="board-item-main" > <div class ="board-item-content" > <div class ="movie-item-info" > <p class ="name" > <a href ="/films/1205" title ="放牛班的春天" data-act ="boarditem-click" data-val ="{movieId:1205}" > 放牛班的春天</a > </p > <p class ="star" > 主演:热拉尔·朱诺,弗朗西斯·贝尔兰德,凯德·麦拉德</p > <p class ="releasetime" > 上映时间:2004-10-16</p > </div > <div class ="movie-item-number score-num" > <p class ="score" > <i class ="integer" > 9.</i > <i class ="fraction" > 6</i > </p > </div > </div > </div >
接下来,检查第二部影片的代码段,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <div class ="board-item-main" > <div class ="board-item-content" > <div class ="movie-item-info" > <p class ="name" > <a href ="/films/341219" title ="穿靴子的猫2" data-act ="boarditem-click" data-val ="{movieId:341219}" > 穿靴子的猫2</a > </p > <p class ="star" > 主演:安东尼奥·班德拉斯,萨尔玛·海耶克,哈维·吉兰</p > <p class ="releasetime" > 上映时间:2022-12-23</p > </div > <div class ="movie-item-number score-num" > <p class ="score" > <i class ="integer" > 9.</i > <i class ="fraction" > 3</i > </p > </div > </div > </div >
对比可发现,每部影片的除了信息不同之外,它们的 HTML 结构是相同的。比如,每部影片都使用 <dd></dd> 标签包裹起来。
这里我们只检查了两部影片,在实际编写时,你可以多检查几部,从而确定它们的 HTML 结构是相同的。
实例:爬虫抓取百度贴吧数据 有了上面的知识储备,这里来看一个 Python 爬虫实战案例:抓取百度贴吧信息(某贴吧下多个页面信息),并将其保存至本地。
案例说明:抓取 百度贴吧 搜索关键词(Python)后检索到的 Python 吧 中前 5 个页面信息 >>>>
以下案例流程为 >>> 编写网络爬虫脚本的通用流程 :
预分析 在开始编写网络爬虫脚本之前,你需要对待爬取的页面进行如下分析:
[1] >>> 判断页面类型
分析方法 >>> 如果页面中的所有数据信息都包含在其 HTML 文档中,那么当前待爬取的页面属于静态页面,而网页数据存在异步加载的页面为动态页面。
以案例为例,具体操作为:打开百度贴吧,搜索 Python,在出现的页面中复制任意一段信息,比如 解决一切python问题,然后点击右键选择查看源码(View Page Source),并使用 Ctrl+F 快捷键在源码页面搜索刚刚复制的数据。
故,可以判断出 >>>> 抓取的百度贴吧页面属于静态网页。
[2] >>> 分析 URL 变化规律
接下来,你需要寻找待爬取百度贴吧页面的 URL 规律(用于后续的请求发送以获取带爬取页面的 HTML 信息):
搜索 “Python” 后,此贴吧第一页的的 URL 如下所示:
1 https://tieba.baidu.com/f?ie=utf-8&kw=python&fr=search
点击第二页,其 URL 信息如下:
1 https://tieba.baidu.com/f?kw=python&ie=utf-8&pn=50
点击第三页,其 URL 信息如下:
1 https://tieba.baidu.com/f?kw=python&ie=utf-8&pn=100
重新点击第一页,其 URL 信息如下:
1 https://tieba.baidu.com/f?kw=python&ie=utf-8&pn=0
如果还不确定,你可以继续多浏览几页。你可以发现 URL 具有两个关键查询参数,分别是 kw 和 pn,并且 pn 参数具有规律性:
1 2 3 4 5 6 7 8 9 第 N 页:pn = (n-1) * 50 # 查询参数: pn = (pageNum - 1) * 50 # 查询参数字典: params = { "kw": "python", "pn": "str(pn)" }
故,百度贴吧页面访问 URL 规则可以简写为:
1 https://tieba.baidu.com/f?kw=python&pn=(pageNum-1)*50
[3] >>> 审查网页结构以及元素节点信息
一般情况下,为了提取页面中的期望信息,在编写网络爬虫脚本前你还必须审查 期望信息在 HTML 文档中的结构以及元素节点信息 以确定内容提取的解析表达式。审查方法可参考上文,解析表达式可参见下文。
这里,因为我们抓取的是整个页面,故不需要进一步审查。
网络爬虫编写 这里,以面向对象的编程设计思路,给出案例的爬虫脚本代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import timeimport urllib.parseimport urllib.requestimport fake_useragentimport randomclass TiebaSpider (object def __init__ (self ): self.url = "https://tieba.baidu.com/f?{}" def requestHTML (self, url ): ua = fake_useragent.UserAgent() ua_info = ua.random headers = { "User-Agent" : ua_info, } req = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(req) html = response.read().decode("utf-8" ) return html def parseHTML (self ): pass def dataSave (self, filename, data ): with open (filename, "w" , encoding="utf-8" ) as f: f.write(data) def run (self ): name = input ("Input Tieba Name: " ) pnum_start = int (input ("Input Start Page: " )) pnum_end = int (input ("Input Abort Page: " )) for page in range (pnum_start, pnum_end+1 ): page_num = (page - 1 ) * 50 params = { "kw" : name, "pn" : str (page_num) } url = self.url.format (urllib.parse.urlencode(params)) html = self.requestHTML(url) filename = "{}-{}p.html" .format (name, page) self.dataSave(filename, html) print("Page %d was successfully crawled" % page) time.sleep(random.randint(1 , 2 )) if __name__ == "__main__" : print("| >>>>>>>>>>>> Start Spider <<<<<<<<<<<< |" ) start = time.time() spider = TiebaSpider() spider.run() end = time.time() print("Script Runtime:%.2f s" % (end - start)) print("| >>>>>>>>>>>> Close Spider <<<<<<<<<<<< |" )
程序执行结果(数据文件保存在当前工作目录下):
1 2 3 4 5 6 7 8 9 | >>>>>>>>>>>> Start Spider <<<<<<<<<<<< | Input Tieba Name: Python Input Start Page: 1 Input Abort Page: 3 Page 1 was successfully crawled Page 2 was successfully crawled Page 3 was successfully crawled Script Runtime:16.51 s | >>>>>>>>>>>> Close Spider <<<<<<<<<<<< |
爬虫程序结构解析 >>>
用面向对象的方法编写爬虫程序时,逻辑结构较为固定,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class xxxSpider (object def __init__ (self ): def requestHTML (self ): def parseHTML (self ): def dataSave (self ): def run (self ): if __name__ == '__main__' : spider = xxxSpider() spider.run()
爬虫随机休眠 爬虫程序访问网站会非常快,这与正常人类的点击行为非常不符。
因此,你可以通过设置随机休眠,来使爬虫程序更像是人类在访问网站,从而让网站不易察觉是爬虫访问网站:
1 2 time.sleep(random.randint(1 , 2 ))
爬虫随机休眠代价 >>>> 影响程序的执行效率。
页面内容结构解析以提取有效信息 这一章节来看 >>> 如何根据网页内容结构以及元素节点信息,借助 HTML 对象解析工具(Regular Expression/Xpath/Beautiful Soup 4)以解析页面提取有效数据?!!
以 猫眼电影网 榜单页面为例 >>>> 假设我们想要提取:榜单页面中每部电影的名称、主演、上映时间以及评分信息(页面中的特定内容)。
你可以先通过浏览器元素审查工具(Inspect)审查每部影片的 HTML 元素结构:
每一部影片的代码段都类似如下(以第一部为例):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <div class ="board-item-main" > <div class ="board-item-content" > <div class ="movie-item-info" > <p class ="name" > <a href ="/films/1205" title ="放牛班的春天" data-act ="boarditem-click" data-val ="{movieId:1205}" > 放牛班的春天</a > </p > <p class ="star" > 主演:热拉尔·朱诺,弗朗西斯·贝尔兰德,凯德·麦拉德</p > <p class ="releasetime" > 上映时间:2004-10-16</p > </div > <div class ="movie-item-number score-num" > <p class ="score" > <i class ="integer" > 9.</i > <i class ="fraction" > 6</i > </p > </div > </div > </div >
这就涉及到一个问题 >>> 如何从页面的所有 HTML 对象信息中仅提取 >>> 每部电影的名称、主演、上映时间以及评分???
你需要编写 >>> 可以匹配目标信息(数据)的 解析表达式 ,常见的解析表达式工具有:Regular Expression && Xpath && Beautiful Soup 4。
也就是说,解析表达式(Regular Expression/Xpath/BS 4)可以使得爬虫从整个页面的 HTML 对象信息中,抓取我们所关注的有效信息(数据),而不是整个 HTML。
开始本章节的学习之前,你需要基本掌握正则表达式的基础语法,初学者请参见 [ >>>> 一文学会正则表达式语法 <<<<]。
以正则表达式(Regular Expression)实现解析表达式为例:
Use Built-in Re Lib Python 中内置的 re 模块,用于提供正则表达式支持。
也就是说,通过编写可以匹配 目标信息(或数据) 的正则表达式,然后通过 re 模块提供的文本(字符串)查找方法,可以轻松提取到有效信息(每部电影的名称、主演、上映时间以及评分)。
Re 模块常用爬虫方法 网络爬虫中常用的 re 模块方法如下:
1)re.findall()
re.findall() 方法会根据正则表达式的文本匹配模式(pattern),来匹配目标字符串中内容。其语法格式如下:
1 re.findall(pattern, string, flags=0 )
其中,参数 pattern 为正则表达式;string 参数为匹配的目标字符串;而 flags 表示功能标志位,可用来拓展正则表达式功能。
该函数的返回值是 pattern 匹配内容的列表。需要注意的是,如果正则表达式中含有一个分组,则返回分组所匹配内容字符串的列表(每个字符串元素都是一次成功的匹配);如果含有多个分组,则返回一个元组列表(每个元组元素都是一次成功的匹配,可以包含多个分组内容)。
2)re.split()
re.split() 方法会根据正则匹配内容,来切割目标字符串,返回值是切割后的内容列表。其语法格式如下:
1 re.split(pattern, string, flags=0 )
3)re.sub()
re.sub() 方法会一个替换字符串(replace),来替换正则匹配到的内容,返回值是替换后的字符串。其语法格式如下:
1 re.sub(pattern, replace, string, maxcount, flags=0 )
其中,参数 replace 为替换字符串;maxcount 参数为最多替换基础,默认为全替换;其它参数同上。
4)re.match() && re.search()
re 模块中还支持几乎所有编程语言都支持的 match() 和 search() 方法等等。
关于 flags 功能标志位 >>>
功能标志位的作用是扩展正则表达的匹配功能。常用的 flag 如下所示:
缩写元字符
说明
A
元字符只能匹配 ASCII 码。
I
匹配忽略字母大小写。
S
使得 . 元字符可以匹配换行符。
M
多行模式,使 ^ && $ 可以匹配每一行的开头和结尾位置。
注意:可以同时使用多个功能标志位(| 连接),比如 flags=re.I|re.S。
正则表达式对象方法 绝大部分重要的应用,总是会先将正则表达式编译为正则表达式对象,之后再进行操作,这可以为正则的使用提供一些其它特性。
你可以通过 re 模块提供的 re.compile() 方法来生成一个正则表达式对象,其语法格式如下:
1 regex = re.compile (pattern, flags=0 )
生成正则表达式对象之后,就可以调用其方法以及属性了。
正则表达式对象中也提供了上一小节中提到的所有方法(match、search、findall…),注意新的特性。例如:
1 2 3 regex = re.compile (pattern, flags=0 ) regex.findall(string, pos, endpos)
其中,参数 string 为匹配的目标字符串;pos 参数为目标字符串的开始匹配位置;endpos 参数为目标字符串的结束匹配位置。
是不是感觉用法上更加灵活了???
适合 HTML 文档的正则规则 首先,给出一个使用贪婪以及非贪婪模式来匹配 HTML 元素的实例,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import rehtml = """ <div><p>JavaScript Lesson</p></div> <div><p>Hello JS.</p></div> """ pattern = "<div><p>.*</p></div>" regRex = re.compile (pattern, flags=re.S) res_list = regRex.findall(html) print(res_list) regRex1 = re.compile ("<div><p>.*?</p></div>" , flags=re.S) res_list1 = regRex1.findall(html) print(res_list1)
从输出结果中可以看出,非贪婪模式要更加适合提取 HTML 元素节点中信息 。
我们期望的是,仅提取出 JavaScript Lesson && Hello JS. 信息就可以了,怎么办?!!
肯定有人能想到 findall() 方法中正则表达式包含分组
1 2 3 4 5 6 7 8 9 10 11 12 13 import rehtml = """ <div><p>JavaScript Lesson</p></div> <div><p>Hello JS.</p></div> """ regRex1 = re.compile ("<div><p>(.*?)</p></div>" , flags=re.S) res_list1 = regRex1.findall(html) print(res_list1)
OK~~~
深入解读 Re 库 关于 Python re 正则表达式模块的详细用法可参见 Python 博文系列 [ >>>> Python 教程 <<<<]。
| >>> ============================================== Split Line =========================================== <<< |
事实上,正则表达式(Regular Expression)的语法较为 “复杂”,初学者学习成本较高。
后续,我们会引入第三方的、方便快捷的 Beautiful Soup 4(BS 4)&& lxml 库,以更简单、便捷的方式实现解析表达式。
关于 BS 4 && lxml 库的使用说明可以参见博文系列中 [ >>>> Web Crawler 教程之网络爬虫工具库 <<<<] 中解析库部分的说明。
网页有效信息提取 再回过头来思考本章节开头的问题, 如何使用正则表达式来解析每部影片的代码段(类似如下)以提取 >>> 每部电影的名称、主演、上映时间以及评分???
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <div class ="board-item-main" > <div class ="board-item-content" > <div class ="movie-item-info" > <p class ="name" > <a href ="/films/1205" title ="放牛班的春天" data-act ="boarditem-click" data-val ="{movieId:1205}" > 放牛班的春天</a > </p > <p class ="star" > 主演:热拉尔·朱诺,弗朗西斯·贝尔兰德,凯德·麦拉德</p > <p class ="releasetime" > 上映时间:2004-10-16</p > </div > <div class ="movie-item-number score-num" > <p class ="score" > <i class ="integer" > 9.</i > <i class ="fraction" > 6</i > </p > </div > </div > </div >
实战演练(提取连续两部影片的名称、主演、上映时间以及评分信息):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import rehtml = """ <div class="board-item-main"> <div class="board-item-content"> <div class="movie-item-info"> <p class="name"><a href="/films/1205" title="放牛班的春天" data-act="boarditem-click" data-val="{movieId:1205}">放牛班的春天</a> </p> <p class="star">主演:热拉尔·朱诺,弗朗西斯·贝尔兰德,凯德·麦拉德</p> <p class="releasetime">上映时间:2004-10-16</p> </div> <div class="movie-item-number score-num"> <p class="score"><i class="integer">9.</i><i class="fraction">6</i> </p> </div> </div> </div> <div class="board-item-main"> <div class="board-item-content"> <div class="movie-item-info"> <p class="name"><a href="/films/243" title="阿凡达" data-act="boarditem-click" data-val="{movieId:243}">阿凡达</a> </p> <p class="star">主演:萨姆·沃辛顿,佐伊·索尔达娜,米歇尔·罗德里格兹</p> <p class="releasetime">上映时间:2010-01-04</p> </div> <div class="movie-item-number score-num"> <p class="score"><i class="integer">9.</i><i class="fraction">4</i> </p> </div> </div> </div> """ pattern = r'<div.*?title="(.*?)".*?star">主演:(.*?)</p.*?time">上映时间:(.*?)</p.*?integer">(.*?)</i.*?fraction">(.*?)</i.*?/div>' regRex = re.compile (pattern, flags=re.S) res_list = regRex.findall(html) print(res_list) if res_list: print(20 *"*" ) for item in res_list: print("影片名称:" , item[0 ]) print("影片主演:" , item[1 ]) print("上映时间:" , item[2 ]) print("影片评分:" , item[3 ] + item[4 ]) print(20 *"*" )
输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 [('放牛班的春天', '热拉尔·朱诺,弗朗西斯·贝尔兰德,凯德·麦拉德', '2004-10-16', '9.', '6'), ('阿凡达', '萨姆·沃辛顿,佐伊·索尔达娜,米歇尔·罗德里格兹', '2010-01-04', '9.', '4')] ******************** 影片名称: 放牛班的春天 影片主演: 热拉尔·朱诺,弗朗西斯·贝尔兰德,凯德·麦拉德 上映时间: 2004-10-16 影片评分: 9.6 ******************** 影片名称: 阿凡达 影片主演: 萨姆·沃辛顿,佐伊·索尔达娜,米歇尔·罗德里格兹 上映时间: 2010-01-04 影片评分: 9.4 ********************
持久化存储页面有效信息 获取到页面中的有效信息后,这一章节来看 >>> 如何将这些提取到的有效的信息(数据)存储下来?!!
通过爬虫脚本将有效信息(数据)抓取下来,然后将数据存储在本地文件,或数据库中,这个过程就称为 >>> 数据持久化存储 。
两种常见的数据持久化存储方式:
本地文件存储 CSV 是电子表格(如 Excel)和数据库中最常见的输入、输出文件格式。
CSV 文件,又称为 逗号分隔值文件 ,适用于存储表格数据(数据或字符)。
Python 中内置的 csv 模块,用来提供 CSV 格式文件的读、写操作。
写入 CSV 文件 我们可以,通过 Python csv 模块提供的文件读写类中的方法,来向 CSV 文件中写入数据。
CSV 模块中,常用的写文件类如下:
[1] >>> csv.writer
csv 模块中的 writer 类,可用于向 CSV 文件写入序列化的数据。构建 writer 类的语法格式如下:
1 csv.writer(csvfile, dialect='excel' , **fmtparams)
其中,参数 csvfile 必须是可迭代(Iterator)对象,例如 文件对象(file)或列表(list)等;参数 dialect 指编码风格(方言),默认为 Excel 的风格,也就是使用都好(,)分隔;**fmtparams 格式化参数,用来覆盖之前 dialect 参数指定的编码风格。
关于 **fmtparams 格式化参数,假如你不想使用 Excel 风格,你可以使用如下格式化参数进行覆盖:
delimiter >>> 用来指定写入行内多个数据项的分隔符;quotechar >>> 用来指定引用符,如果数据项内本身包含分隔字符时,为了排除歧义,可以将当前数据项使用引用符引起来表示完整的一个数据项。
逐行写入内容的实例代码如下:
1 2 3 4 5 6 7 8 9 10 11 import csvwith open ("test.csv" , mode="w" , newline="" ) as csvfile: obj_CSVWrite = csv.writer(csvfile, delimiter=" " , quotechar="/" ) obj_CSVWrite.writerow(["Hello" ]*5 + ["JS" ]) obj_CSVWrite.writerow(["Hello" , "JS" , "Welcome to JS World" ])
生成文件 test.csv 内容如下:
1 2 Hello Hello Hello Hello Hello JS Hello JS /Welcome to JS World/
可见文件中,使用 writerow() 方法逐行写入,行内多个数据项以空格(delimiter=" ")分隔,对于本身包含分隔符的数据项会使用斜杠符(quotechar="/")包围以引用。
如何同时写入多行内容 >>>
如果想同时写入多行数据,需要使用 writerrows() 方法:
1 2 3 4 5 6 7 8 9 10 import csvwith open ("test.csv" , mode="w" , newline="" ) as csvfile: obj_CSVWrite = csv.writer(csvfile) obj_CSVWrite.writerows([("Javascript" , "Course" ), ("Spider" , "Course" )])
生成文件 test.csv 内容如下:
1 2 Javascript,Course Spider,Course
[2] >>> csv.DictWriter()
类似于 writer 读写类,可以使用 DictWriter 类向 CSV 文件中以字典(Dict)的形式写入数据。其构建语法格式如下:
1 csv.writer(csvfile, fieldname, **fmtparams)
其中,参数 fieldname 可用于指定表头(表格字段名),对应字典的 Key;其它参数类似 writer。
实例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import csvwith open ("test1.csv" , mode="w" , newline="" ) as csvfile: fieldname = ["first_name" , "last_name" ] obj_CSVWrite = csv.DictWriter(csvfile, fieldnames=fieldname, delimiter="," ) obj_CSVWrite.writeheader() obj_CSVWrite.writerow({"first_name" : "Baked" , "last_name" : "Beans" }) obj_CSVWrite.writerow({"first_name" : "Black" , "last_name" : "John" }) obj_CSVWrite.writerows([{'first_name' : 'Baked' , 'last_name' : 'Beans' },{'first_name' : 'Lovely' , 'last_name' : 'Spam' }])
生成文件 test1.csv 内容如下:
1 2 3 4 5 first_name,last_name Baked,Beans Black,John Baked,Beans Lovely,Spam
读取 CSV 文件 同理,通过 Python csv 模块提供的文件读写类中的方法,来从 CSV 文件中读取数据。
CSV 模块中,常用的读文件类如下:
[1] >>> csv.reader
csv 模块中的 reader 类,可用于从 CSV 文件中读取数据。构建 reader 类的语法格式如下:
1 csv.reader(csvfile, dialect='excel' , **fmtparams)
读取文件 test.csv 内容实例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 import csvwith open ("test.csv" , mode="r" , newline="" ) as csvfile: obj_CSVReader = csv.reader(csvfile, delimiter=" " , quotechar="/" ) for row in obj_CSVReader: print(row)
[2] >>> csv.DictReader
类似于 csv 模块中的 reader 类,DictReader 类可用于从 CSV 文件中以字典的形式读取数据。构建 reader 类的语法格式如下:
1 csv.DictReader(csvfile, filedname, **fmtparams)
读取文件 test1.csv 内容实例代码如下:
1 2 3 4 5 6 7 8 9 10 11 import csvwith open ("test1.csv" , mode="r" , newline="" ) as csvfile: obj_CSVReader = csv.DictReader(csvfile, delimiter="," ) for row in obj_CSVReader: print(row["first_name" ], row["last_name" ])
输出结果如下:
1 2 3 4 Baked Beans Black John Baked Beans Lovely Spam
实例:抓取猫影电影排行榜 有了上面的知识储备,我们来演示一个完整的 Python 爬虫实战案例:抓取 猫眼电影网 TOP100 排行榜 中的影片信息,包括电影名称、上映时间、主演信息以及电影评分。
以下案例流程为 >>> 编写网络爬虫脚本的通用流程 :
[1] >>> 预分析
在开始编写网络爬虫脚本之前,你需要对待爬取的排行榜页面进行如下分析:
1.1】 >>> 判断页面类型
点击右键查看页面源码,确定要抓取的数据是否存在于页面内。
以排行榜为例,具体操作为:猫眼电影网 TOP100 排行榜,在出现的页面中复制任意一部影片的信息,比如 肖申克的救赎 ,然后点击右键选择查看源码(View Page Source),并使用 Ctrl+F 快捷键在源码页面搜索刚刚复制的影片名称。
故,可以判断出 >>>> 抓取的百度贴吧页面属于静态网页。
1.2】 >>> 分析 URL 变化规律
接下来,你需要寻找待爬取TOP100 排行榜页面的 URL 规律(用于后续的请求发送以获取带爬取页面的 HTML 信息):
1 2 3 4 5 第一页 >>> https://www.maoyan.com/board/4?offset=0 第二页 >>> https://www.maoyan.com/board/4?offset=10 第三页 >>> https://www.maoyan.com/board/4?offset=20 ... 第 n 页 >>> https://www.maoyan.com/board/4?offset=(n-1)*10
1.3】 >>> 审查网页结构以及元素节点信息以确定解析表达式
审查 期望信息在 HTML 文档中的结构以及元素节点信息 以确定内容提取的解析表达式:
1 2 3 4 5 6 7 8 9 10 11 12 <div class ="board-item-main" > <div class ="board-item-content" > <div class ="movie-item-info" > <p class ="name" > <a href ="/films/1200486" title ="我不是药神" data-act ="boarditem-click" data-val ="{movieId:1200486}" > 我不是药神</a > </p > <p class ="star" > 主演:徐峥,周一围,王传君</p > <p class ="releasetime" > 上映时间:2018-07-05</p > </div > <div class ="movie-item-number score-num" > <p class ="score" > <i class ="integer" > 9.</i > <i class ="fraction" > 6</i > </p > </div > </div > </div >
使用 Chrome 开发者调试工具来精准定位要抓取信息的元素结构。之所以这样做,是因为这能避免正则表达式的冗余,提高编写正则表达式的速度。最终正则表达式如下:
1 <div class="board-item-main">.*?title="(.*?)".*?class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>
正则表达式中,将需要提取的信息使用 (.*?) 代替,而不需要的内容(包括元素标签)使用 .*? 代替。
[2] >>> 网络爬虫编写
这里,以面向对象的编程设计思路,给出案例的爬虫脚本代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 import timeimport urllib.parseimport urllib.requestimport fake_useragentimport reimport csvimport randomclass MaoyanSpider (object def __init__ (self ): self.url = "https://www.maoyan.com/board/4?{}" self.counter = 0 def requestHTML (self, url ): ua = fake_useragent.UserAgent() ua_info = ua.edge headers = { "User-Agent" : ua_info, "Cookie" : "你本机浏览器的 Cookie" } req = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(req) html = response.read().decode("utf-8" ) return html def parseHTML (self, pattern, html ): regExp_Obj = re.compile (pattern=pattern, flags=re.S) find_res = regExp_Obj.findall(html) return find_res def dataSave (self, filename, validData ): with open (filename, "a" , newline="" , encoding="utf-8" ) as csvfile: csvWriter_Obj = csv.writer(csvfile) if validData: for record in validData: video_name = record[0 ].strip() video_actor = record[1 ].strip()[3 :] video_time = record[2 ].strip()[5 :] video_score = record[3 ] + record[4 ] lineData = [video_name, video_time, video_actor, video_score] csvWriter_Obj.writerow(lineData) if (self.counter < 10 ): print(video_name, video_time, video_actor, video_score) self.counter = self.counter + 1 else : print("Request Failed" ) def run (self ): pnum_start = 1 pnum_end = 10 for page in range (pnum_start, pnum_end+1 ): page_num = (page - 1 ) * 10 params = { "offset" : page_num } url = self.url.format (urllib.parse.urlencode(params)) html = self.requestHTML(url) pattern = '<div class="board-item-main">.*?title="(.*?)".*?class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>' validData_list = self.parseHTML(pattern, html) filename = "maoyanTop100.csv" self.dataSave(filename, validData_list) print("Page %d was successfully crawled" % page) time.sleep(random.randint(1 , 2 )) if __name__ == "__main__" : print("| >>>>>>>>>>>> Start Spider <<<<<<<<<<<< |" ) start = time.time() try : spider = MaoyanSpider() spider.run() except Exception as e: print("Error: " , e) end = time.time() print("Script Runtime:%.2f s" % (end - start)) print("| >>>>>>>>>>>> Close Spider <<<<<<<<<<<< |" )
输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | >>>>>>>>>>>> Start Spider <<<<<<<<<<<< | 我不是药神 2018-07-05 徐峥,周一围,王传君 9.6 肖申克的救赎 1994-09-10(加拿大) 蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿 9.5 海上钢琴师 2019-11-15 蒂姆·罗斯,比尔·努恩 ,克兰伦斯·威廉姆斯三世 9.3 绿皮书 2019-03-01 维果·莫腾森,马赫沙拉·阿里,琳达·卡德里尼 9.5 霸王别姬 1993-07-26 张国荣,张丰毅,巩俐 9.4 美丽人生 2020-01-03 罗伯托·贝尼尼,朱斯蒂诺·杜拉诺,赛尔乔·比尼·布斯特里克 9.3 小偷家族 2018-08-03 中川雅也,安藤樱,松冈茉优 8.1 这个杀手不太冷 1994-09-14(法国) 让·雷诺,加里·奥德曼,娜塔莉·波特曼 9.4 哪吒之魔童降世 2019-07-26 吕艳婷,囧森瑟夫,瀚墨 9.6 怦然心动 2010-07-26(美国) 玛德琳·卡罗尔,卡兰·麦克奥利菲,艾丹·奎因 8.9 Page 1 was successfully crawled Page 2 was successfully crawled Page 3 was successfully crawled Page 4 was successfully crawled Page 5 was successfully crawled Page 6 was successfully crawled Page 7 was successfully crawled Page 8 was successfully crawled Page 9 was successfully crawled Page 10 was successfully crawled Script Runtime:19.87 s | >>>>>>>>>>>> Close Spider <<<<<<<<<<<< |
同时,查看当前工作目录下的生成的数据存储文件 maoyanTop100.csv,可以看到抓取到的 100 条影片数据。
开始之前,相信你已经掌握了 SQL 语言的基本语法 >>>
数据库存储 上面我们将提取到的网页有效数据存储到了本地 CSV 格式的文件中,这里来看如何将有效数据存储至 MySQL 数据库?!!
Python 第三方的 pymysql 模块,用于提供 Python 连接,以及操作 MySQL 数据库。安装方法如下:
库以及存储数据表准备 首先,你应该确保你安装有可供测试、使用的 MySQL 数据库。然后,在 DOS 下进行如下操作以构建用于存储有效数据的库以及数据表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 1. 开启 MySQL 服务(未开启时): > net start mysql MySQL 服务正在启动 . MySQL 服务已经启动成功。 # 2. 连接 MySQL 数据库: > mysql -h 127.0.0.1 -u root -padmin mysql> # 3. 构建库: mysql> CREATE DATABASE maoyandb CHARSET UTF8; Query OK, 1 row affected (0.00 sec) # 4. 切换库: mysql> USE maoyandb Database changed # 5. 构建数据表 mysql> CREATE TABLE filmtb ( -> name varchar(50), -> time varchar(30), -> actor varchar(100), -> score varchar(10) -> ); Query OK, 0 rows affected (0.01 sec)
Use Third-Party Pymysql 网络爬虫相关的 MySQL 操作:
[1] >>> 连接数据库
1 db = pymysql.connect(host="localhost/ip" , user, password, database)
其中,参数 host 用来指定 MySQL 数据库地址,可以是本地服务端地址,也可以是远程数据库 IP 地址;参数 user 用来指定用于连接数据库的用户名;password 参数用于指定连接数据库的用户密码;database 用来指定想要连接的数据库名称。
[2] >>> 构建游标对象
1 cursorObject = db.cursor()
[3] >>> 执行 sql 语句
cursor 对象提供的 execute() 语句用于执行 sql 语句,以实现数据库表的增、删、改、查等操作。如下:
1 2 3 4 5 6 7 sql = "insert into filmtb values('%s', '%s', '%s', '%s')" % ('我不是药神' , '2018-07-05' , '徐峥,周一围,王传君' , '9.6' ) cursorObject.execute(sql) sql = "insert into filmtb values(%s, %s, %s, %s)" cursorObject.execute(sql, ['我不是药神' , '2018-07-05' , '徐峥,周一围,王传君' , '9.6' ])
[4] >>> 提交数据
[5] >>> 资源释放
1 2 3 4 cursorObject.close() db.close()
存储实例 向数据库表中插入一条数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import pymysqldb = pymysql.connect(host="localhost" , user="root" , password="admin" , database="maoyandb" ) cursorObj = db.cursor() data_list = ['我不是药神' , '2018-07-05' , '徐峥,周一围,王传君' , '9.6' ] sql = "insert into filmtb values(%s, %s, %s, %s)" cursorObj.execute(sql, data_list) db.commit() cursorObj.close() db.close()
DOS 下连接数据库查询数据结果,如下:
1 2 3 4 5 6 7 mysql> SELECT * FROM FILMTB; +-----------------+------------+----------------------------+-------+ | name | time | actor | score | +-----------------+------------+----------------------------+-------+ | 我不是药神 | 2018-07-05 | 徐峥,周一围,王传君 | 9.6 | +-----------------+------------+----------------------------+-------+ 1 row in set (0.00 sec)
多条数据同时插入 >>>
cursor 对象还提供了一种更效率的插入方法 executemany(),支持同时向表中插入多条数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import pymysqldb = pymysql.connect(host="localhost" , user="root" , password="admin" , database="maoyandb" ) cursorObj = db.cursor() dataTuple_list = [("肖申克的救赎" , "1994-09-10" , "蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿" , "9.5" ), ("海上钢琴师" , "2019-11-15" , "蒂姆·罗斯,比尔·努恩 ,克兰伦斯·威廉姆斯三世" , "9.3" )] sql = "insert into filmtb values(%s, %s, %s, %s)" cursorObj.executemany(sql, dataTuple_list) db.commit() cursorObj.close() db.close()
DOS 下连接数据库查询数据结果,如下:
1 2 3 4 5 6 7 8 9 mysql> SELECT * FROM FILMTB; +--------------------+------------+-----------------------------------------------------------------+-------+ | name | time | actor | score | +--------------------+------------+-----------------------------------------------------------------+-------+ | 我不是药神 | 2018-07-05 | 徐峥,周一围,王传君 | 9.6 | | 肖申克的救赎 | 1994-09-10 | 蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿 | 9.5 | | 海上钢琴师 | 2019-11-15 | 蒂姆·罗斯,比尔·努恩 ,克兰伦斯·威廉姆斯三世 | 9.3 | +--------------------+------------+-----------------------------------------------------------------+-------+ 3 rows in set (0.00 sec)
实例:抓取猫影电影排行榜 预分析过程同【4.2】小节,这里我们使用数据库的存储方法重写【4.2】小节中的网络爬虫脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 import timeimport urllib.parseimport urllib.requestimport fake_useragentimport reimport pymysqlimport randomclass MaoyanSpider (object def __init__ (self ): self.url = "https://www.maoyan.com/board/4?{}" self.db = pymysql.connect(host="localhost" , user="root" , password="admin" , database="maoyandb" , charset="utf8" ) self.cursorObject = self.db.cursor() self.counter = 0 def requestHTML (self, url ): ua = fake_useragent.UserAgent() ua_info = ua.edge headers = { "User-Agent" : ua_info, "Accept" : "*/*" , "Cookie" : "__mta=146102795.1672499681444.1673112786612.1673166343246.9; uuid_n_v=v1; uuid=D815AEF0891D11ED8B7C3F15132DB86FB3A3D5406DE64D05805D9B914B5EC73D; _csrf=c0b537815f7f65bdd82c6a2df76280c3a4cc2ba75dbac1113793e4c716926538; _lxsdk_cuid=18568bfd59ec8-063f8bb1638243-7a575473-144000-18568bfd59ec8; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1672499681; _lxsdk=D815AEF0891D11ED8B7C3F15132DB86FB3A3D5406DE64D05805D9B914B5EC73D; __mta=146102795.1672499681444.1673111960576.1673112438542.42; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1673166343; _lxsdk_s=185907c46cf-0b7-a45-7b0%7C%7C4" } req = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(req) html = response.read().decode("utf-8" ) return html def parseHTML (self, pattern, html ): regExp_Obj = re.compile (pattern=pattern, flags=re.S) find_res = regExp_Obj.findall(html) return find_res def dataSave (self, validData ): dataRepo = [] if validData: for record in validData: video_name = record[0 ].strip() video_actor = record[1 ].strip()[3 :] video_time = record[2 ].strip()[5 :15 ] video_score = record[3 ] + record[4 ] dataItem = (video_name, video_time, video_actor, video_score) dataRepo.append(dataItem) if (self.counter < 10 ): print(str (dataItem)) self.counter = self.counter + 1 sql = "insert into filmtb values (%s, %s, %s, %s)" try : self.cursorObject.executemany(sql, dataRepo) self.db.commit() except Exception as e: print("Error: " , e) self.db.rollback() else : print("Request Failed" ) def run (self ): pnum_start = 1 pnum_end = 10 for page in range (pnum_start, pnum_end+1 ): page_num = (page - 1 ) * 10 params = { "offset" : page_num } url = self.url.format (urllib.parse.urlencode(params)) html = self.requestHTML(url) pattern = '<div class="board-item-main">.*?title="(.*?)".*?class="star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>' validData_list = self.parseHTML(pattern, html) self.dataSave(validData_list) print("Page %d was successfully crawled" % page) time.sleep(random.randint(1 , 2 )) self.cursorObject.close() self.db.close() if __name__ == "__main__" : print("| >>>>>>>>>>>> Start Spider <<<<<<<<<<<< |" ) start = time.time() spider = MaoyanSpider() spider.run() end = time.time() print("Script Runtime:%.2f s" % (end - start)) print("| >>>>>>>>>>>> Close Spider <<<<<<<<<<<< |" )
数据库查询存储结果,如下所示(篇幅原因,只截取一部分):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 mysql> SELECT * FROM FILMTB; +---------------------------------+--------------------+-----------------------------------------------------------------------------------------+-------+ | name | time | actor | score | +---------------------------------+--------------------+-----------------------------------------------------------------------------------------+-------+ | 我不是药神 | 2018-07-05 | 徐峥,周一围,王传君 | 9.6 | | 肖申克的救赎 | 1994-09-10 | 蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿 | 9.5 | | 海上钢琴师 | 2019-11-15 | 蒂姆·罗斯,比尔·努恩 ,克兰伦斯·威廉姆斯三世 | 9.3 | | 绿皮书 | 2019-03-01 | 维果·莫腾森,马赫沙拉·阿里,琳达·卡德里尼 | 9.5 | | 霸王别姬 | 1993-07-26 | 张国荣,张丰毅,巩俐 | 9.4 | | 美丽人生 | 2020-01-03 | 罗伯托·贝尼尼,朱斯蒂诺·杜拉诺,赛尔乔·比尼·布斯特里克 | 9.3 | | 小偷家族 | 2018-08-03 | 中川雅也,安藤樱,松冈茉优 | 8.1 | | 这个杀手不太冷 | 1994-09-14 | 让·雷诺,加里·奥德曼,娜塔莉·波特曼 | 9.4 | .... .... .... | 波西米亚狂想曲 | 2019-03-22 | 拉米·马雷克,本·哈迪,约瑟夫•梅泽罗 | 9.4 | | 真爱至上 | 2003-11-21 | 休·格兰特,比尔·奈伊,连姆·尼森 | 8.6 | | 大鱼 | 2003-12-04 | 伊万·麦克格雷格,阿尔伯特·芬尼,杰西卡·兰格 | 8.6 | | 模仿游戏 | 2015-07-21 | 本尼迪克特·康伯巴奇,凯拉·奈特莉,马修·古迪 | 9.3 | | 血战钢锯岭 | 2016-12-08 | 安德鲁·加菲尔德,雨果·维文,卢克·布雷西 | 9.3 | | 傲慢与偏见 | 2008-02-10 | 马修·麦克费登,吉娜·马隆,妲露拉·莱莉 | 8.4 | | 致命魔术 | 2006-10-17 | 休·杰克曼,克里斯蒂安·贝尔,迈克尔·凯恩 | 8.8 | | 奇迹男孩 | 2018-01-19 | 雅各布·特瑞布雷,朱莉娅·罗伯茨,欧文·威尔逊 | 9.2 | | 禁闭岛 | 2010-02-13 | 莱昂纳多·迪卡普里奥,马克·鲁法洛,本·金斯利 | 8.7 | | 鬼子来了 | 2000-05-13 | 姜文,姜宏波,陈强 | 8.9 | +---------------------------------+--------------------+-----------------------------------------------------------------------------------------+-------+ 100 rows in set (0.01 sec)
可见,爬虫脚本已将猫眼电影 TOP100 排行榜中的所有影片信息全部抓取存储到了数据库表中。
网络爬虫常见问题 这一小节来看网络爬虫常见问题以及其解决方法:
百度安全验证问题 爬虫抓取百度搜索页面信息时,你可能会发现抓取到的内容不是网页信息,响应内容显示:百度安全验证 & 网络不给力,请稍后重试 & 返回首页 & 问题反馈 。如下显示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <!DOCTYPE html > <html lang ="zh-CN" > <head > <meta charset ="utf-8" > <title > 百度安全验证</title > <meta http-equiv ="Content-Type" content ="text/html; charset=utf-8" > <meta name ="apple-mobile-web-app-capable" content ="yes" > <meta name ="apple-mobile-web-app-status-bar-style" content ="black" > <meta name ="viewport" content ="width=device-width, user-scalable=no, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0" > <meta name ="format-detection" content ="telephone=no, email=no" > <link rel ="shortcut icon" href ="https://www.baidu.com/favicon.ico" type ="image/x-icon" > <link rel ="icon" sizes ="any" mask href ="https://www.baidu.com/img/baidu.svg" > <meta http-equiv ="X-UA-Compatible" content ="IE=Edge" > <meta http-equiv ="Content-Security-Policy" content ="upgrade-insecure-requests" > <link rel ="stylesheet" href ="https://ppui-static-wap.cdn.bcebos.com/static/touch/css/api/mkdjump_aac6df1.css" /> </head > <body > <div class ="timeout hide" > <div class ="timeout-img" > </div > <div class ="timeout-title" > 网络不给力,请稍后重试</div > <button type ="button" class ="timeout-button" > 返回首页</button > </div > <div class ="timeout-feedback hide" > <div class ="timeout-feedback-icon" > </div > <p class ="timeout-feedback-title" > 问题反馈</p > </div > <script src ="https://wappass.baidu.com/static/machine/js/api/mkd.js" > </script > <script src ="https://ppui-static-wap.cdn.bcebos.com/static/touch/js/mkdjump_db105ab.js" > </script > </body > </html >
通过查阅资料了解到,出现此问题可能是请求头(Request Headers)定义不完善被百度反爬(大多数是因为请求头缺少 Accept),还有可能是因为未登录时获取无效 Cookie 来定义请求头等。
解决思路 >>> 需要进一步重构请求头信息,以实现更真实的浏览器请求伪装。
解决办法 >>>>
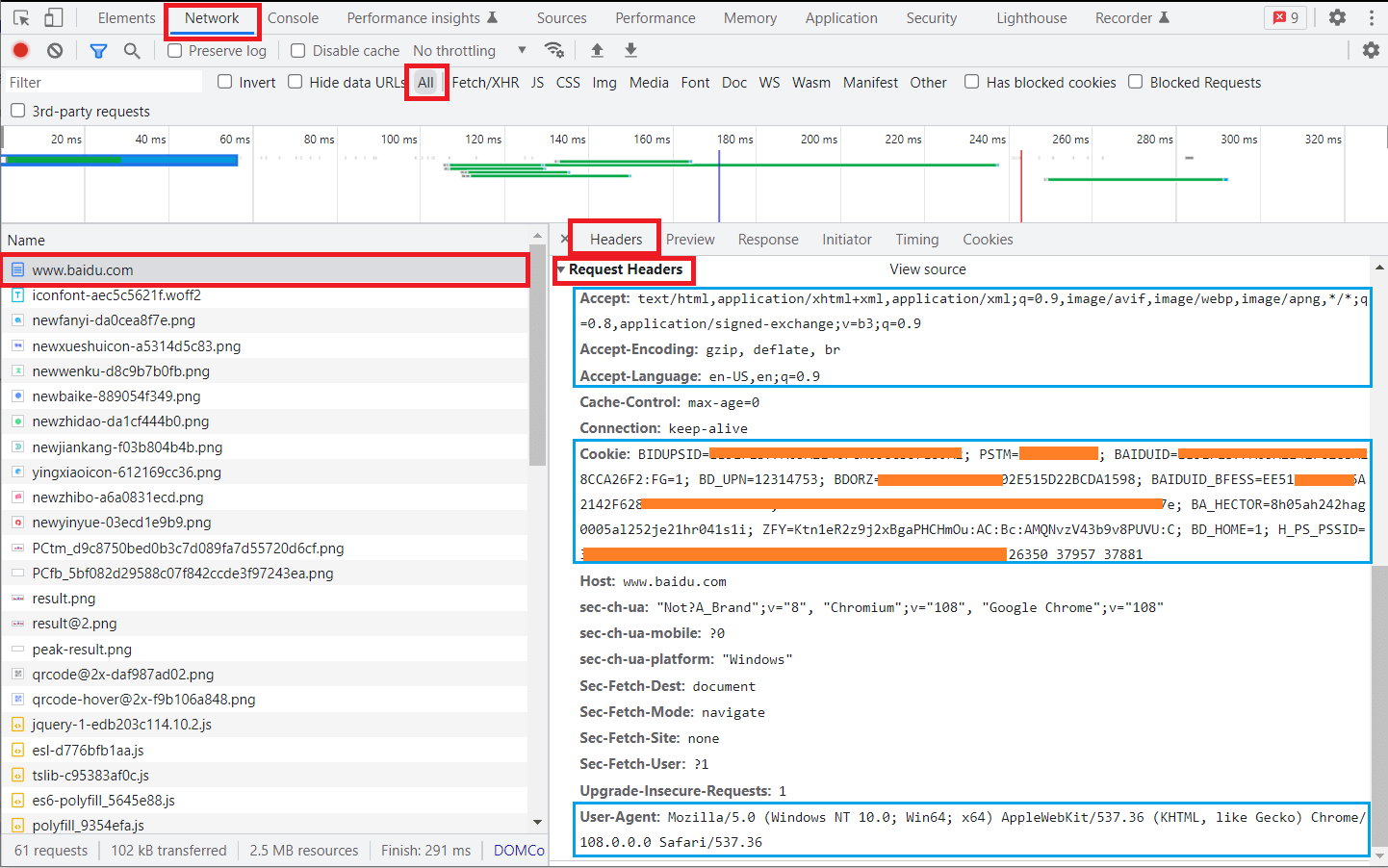
收集浏览器中百度搜索页面的请求头(Request Headers)信息,如下图:
你可以将 Accept && Cookie 的键值对 Copy 下来,用于重构爬虫的请求头:
1 2 3 4 header{ "Cookie" : '填写你浏览器的 Cookie 值' , "Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9" , }
HTTP Error 302 有时爬虫在抓取某些网站时,可能出现如下错误:
1 2 HTTPError: HTTP Error 302 : The HTTP server returned a redirect error that would lead to an infinite loop. The last 30x error message was: .....
查询资料,发现是请求资源发生重定向导致无限循环的错误,这也是网站反爬机制的一种。
解决方法一 >>>
一种原因可能是请求时没有 Cookie,被网站反爬。你可以通过重构请求头,为请求添加 Cookie。
解决方法二 >>>
看到有一篇博文说,可以使用 Requests 库来发送请求,可以作为一种尝试方法。